from joblib import Parallel, delayed
#device = 'cuda' if torch.cuda.is_available() else 'cpu'
device = 'cpu' # problem is small, so not much help from cuda
num_epochs = 50
sims = 100
maxw = 10
def doubledescentdemo(x, y, xtest, ytest, f, device=device,
num_epochs=num_epochs, sims=sims,
maxw=maxw, lr=0.1):
x=x.to(device)
y=y.to(device).reshape(x.shape[0],1)
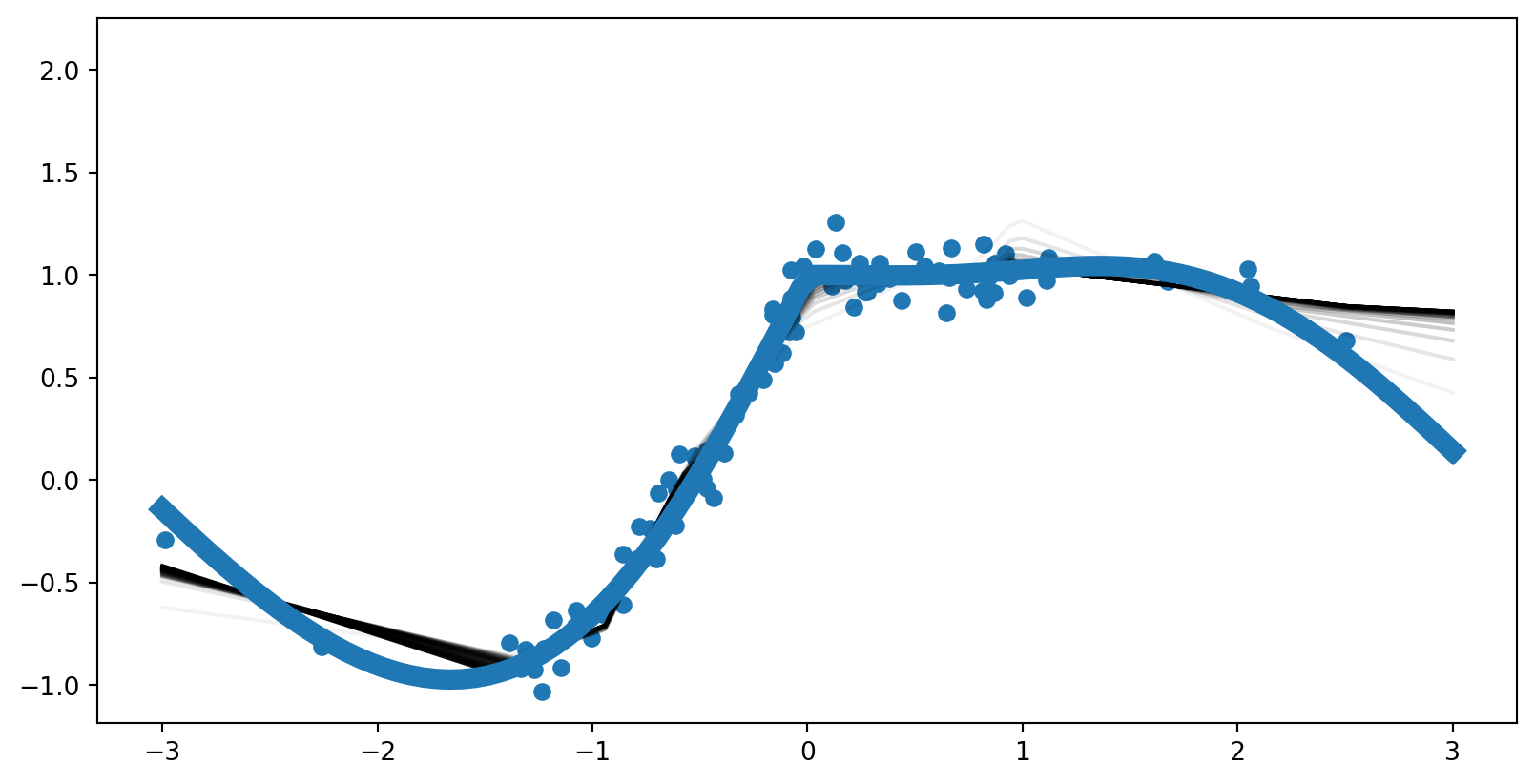
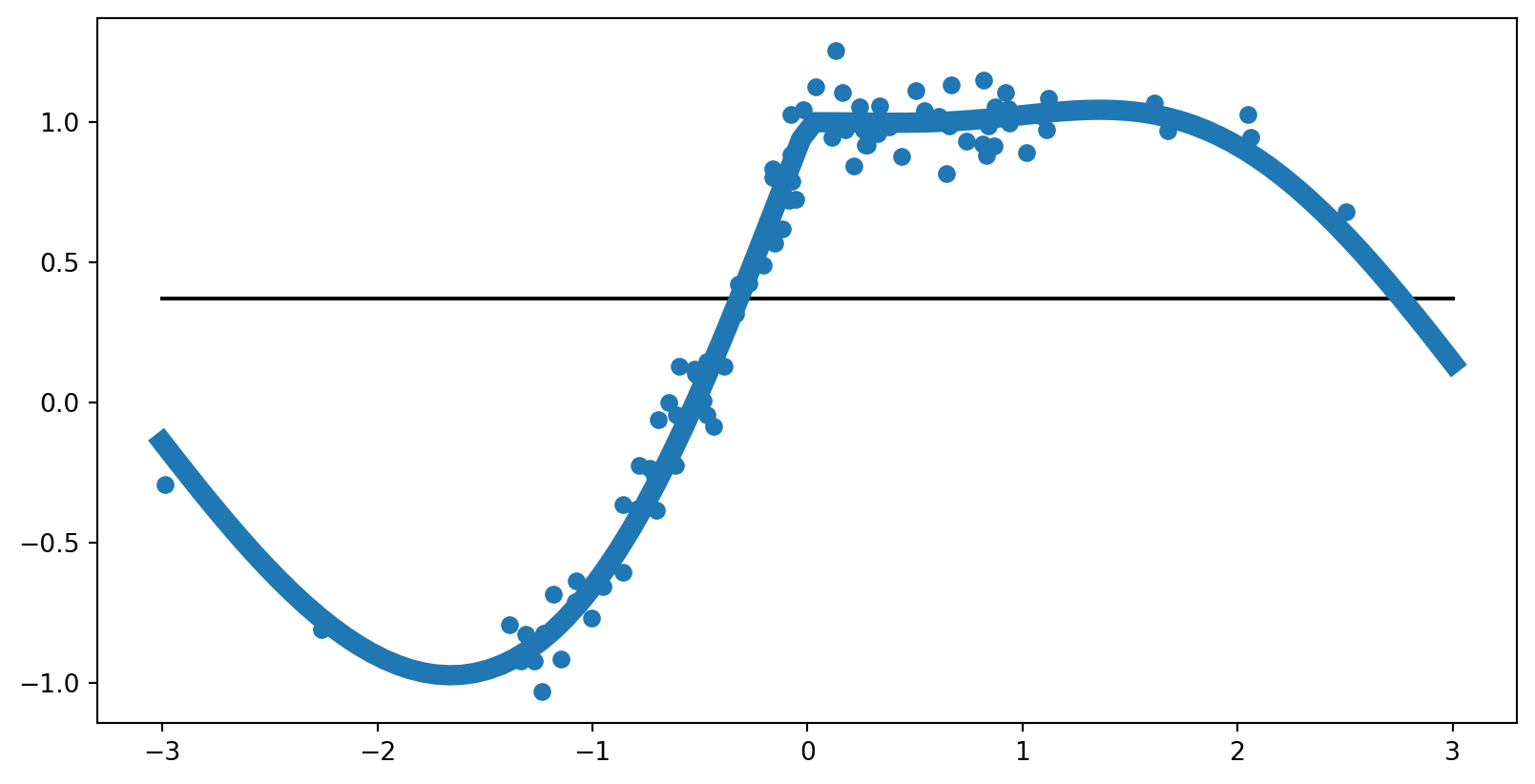
fx = f(x.T).reshape(y.shape).to(device)
ytest = ytest.to(device).reshape(xtest.shape[0],1)
xtest = xtest.to(device)
loss_fn = nn.MSELoss().to(device)
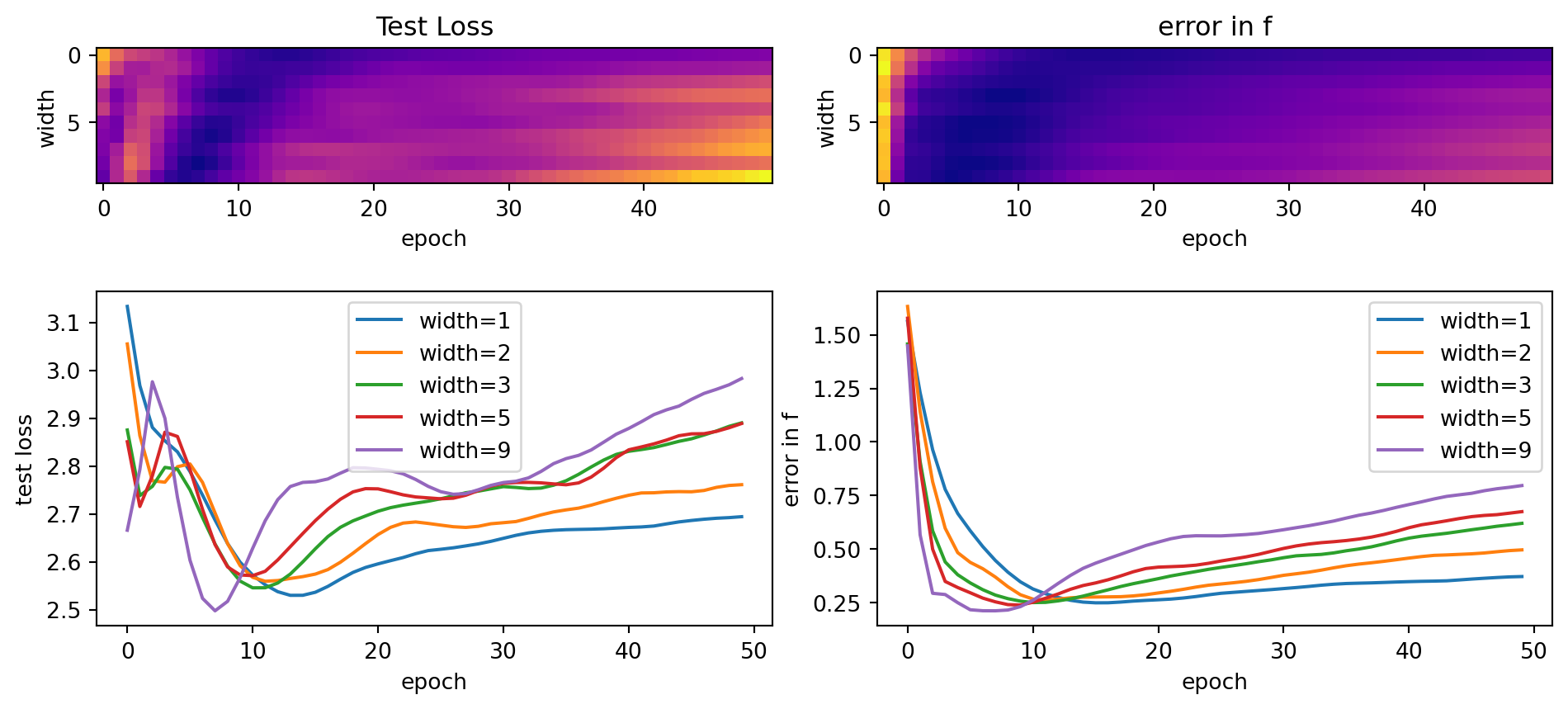
losses = np.zeros([maxw,num_epochs,sims])
nonoise = np.zeros([maxw,num_epochs,sims])
def dd(w):
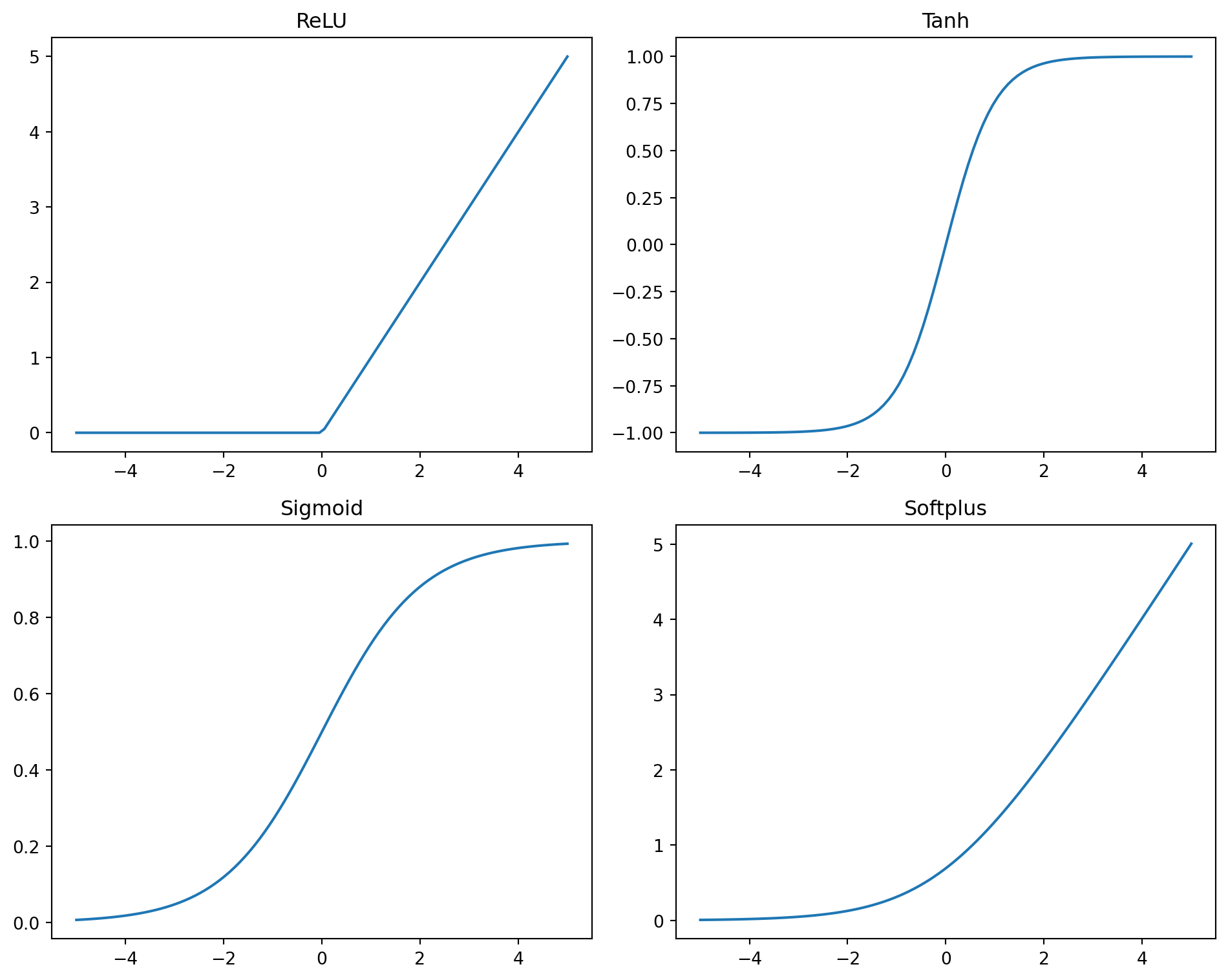
mlp = multilayer(x.shape[1],w+1,1,nn.ReLU()).to(device)
optimizer = torch.optim.Adam(mlp.parameters(), lr=lr)
losses = np.zeros(num_epochs)
nonoise=np.zeros(num_epochs)
for n in range(num_epochs):
y_pred = mlp(x)
loss = loss_fn(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses[n] = loss_fn(mlp(xtest),ytest).item()
nonoise[n] = loss_fn(y_pred, fx)
mlp.zero_grad()
return([losses, nonoise])
for w in range(maxw):
foo=lambda s: dd(w)
print(f"width {w}")
results = Parallel(n_jobs=20)(delayed(foo)(s) for s in range(sims))
for s in range(sims):
losses[w,:,s] = results[s][0]
nonoise[w,:,s] = results[s][1]
return([losses, nonoise])