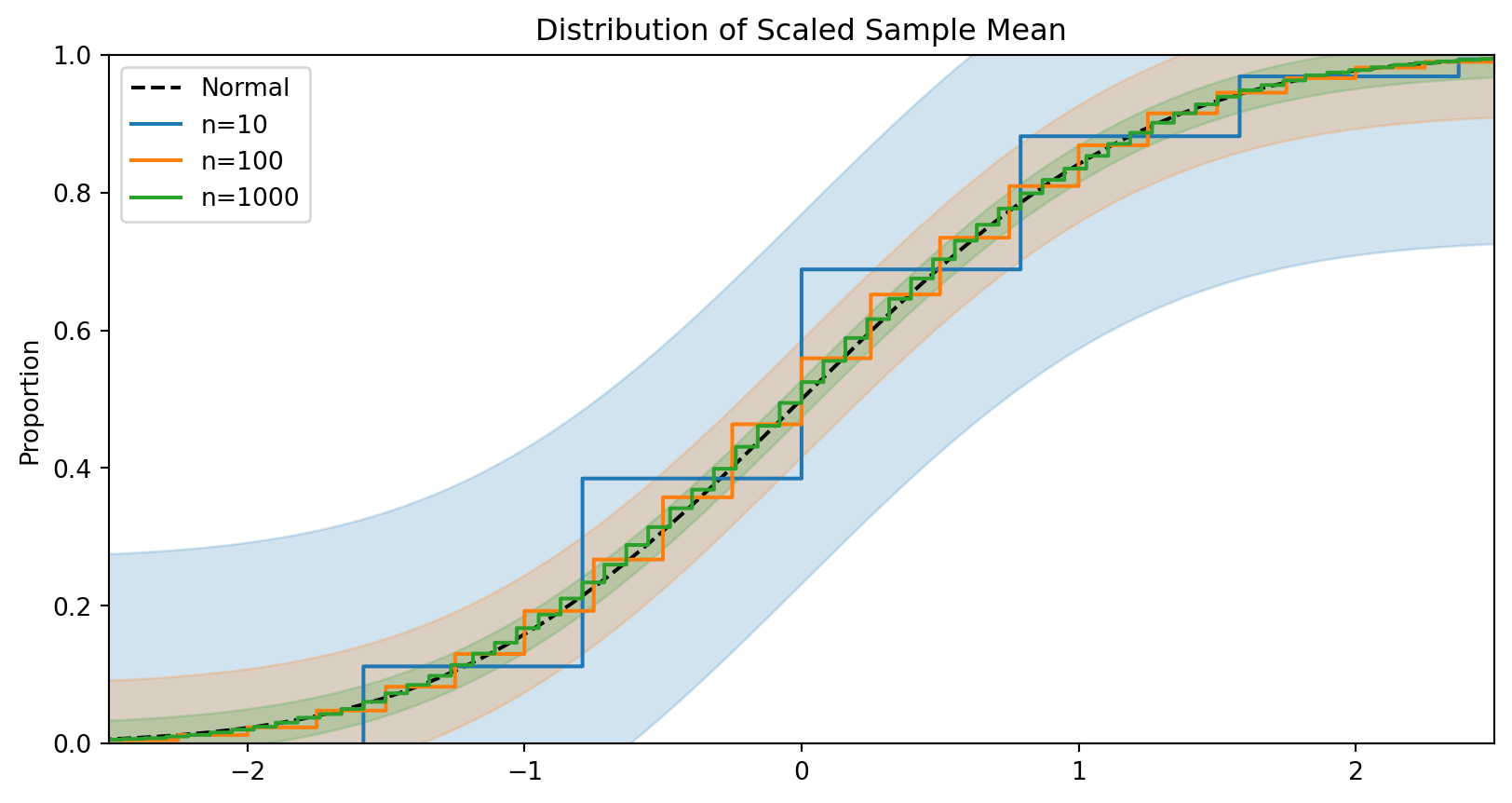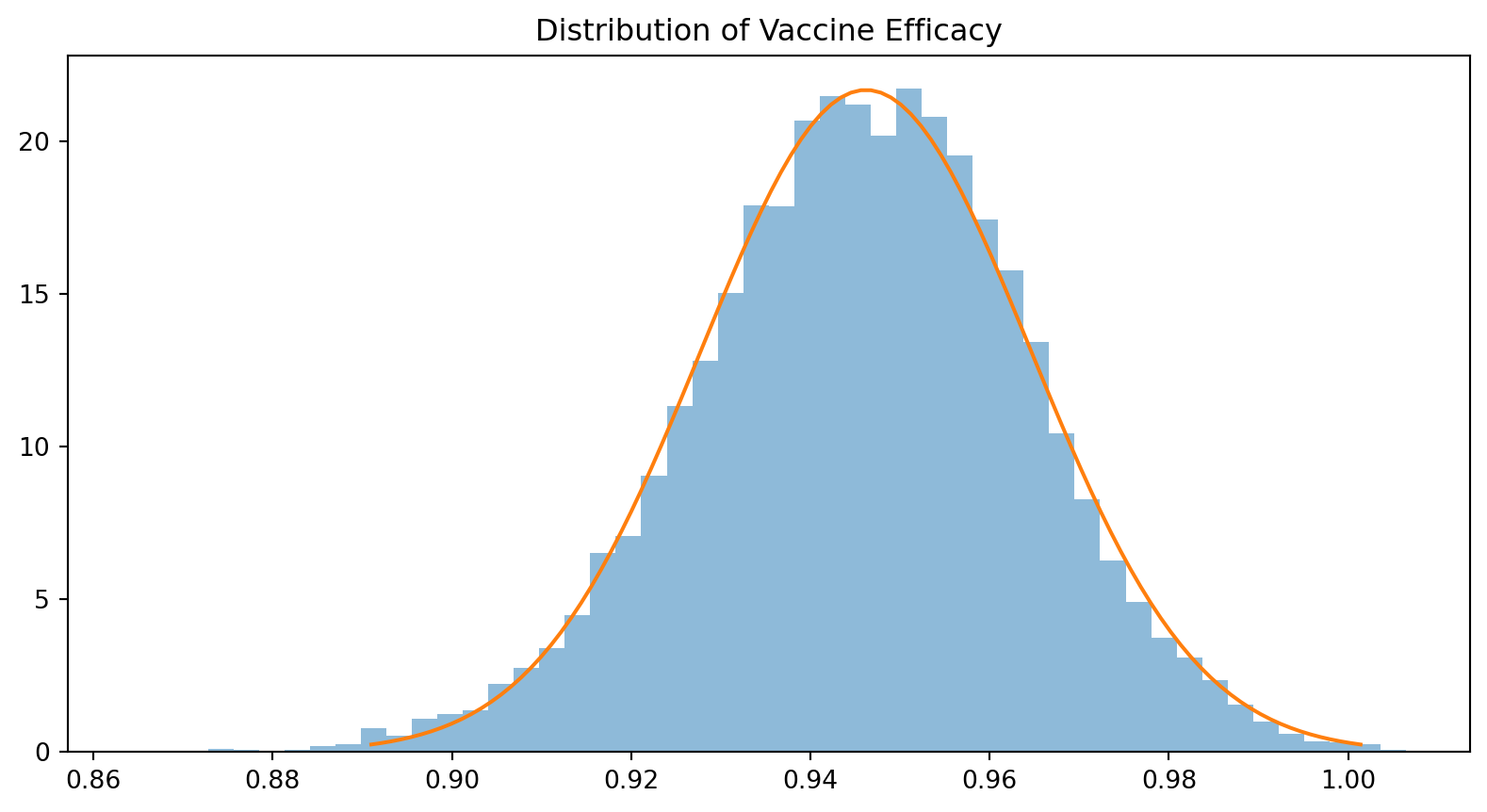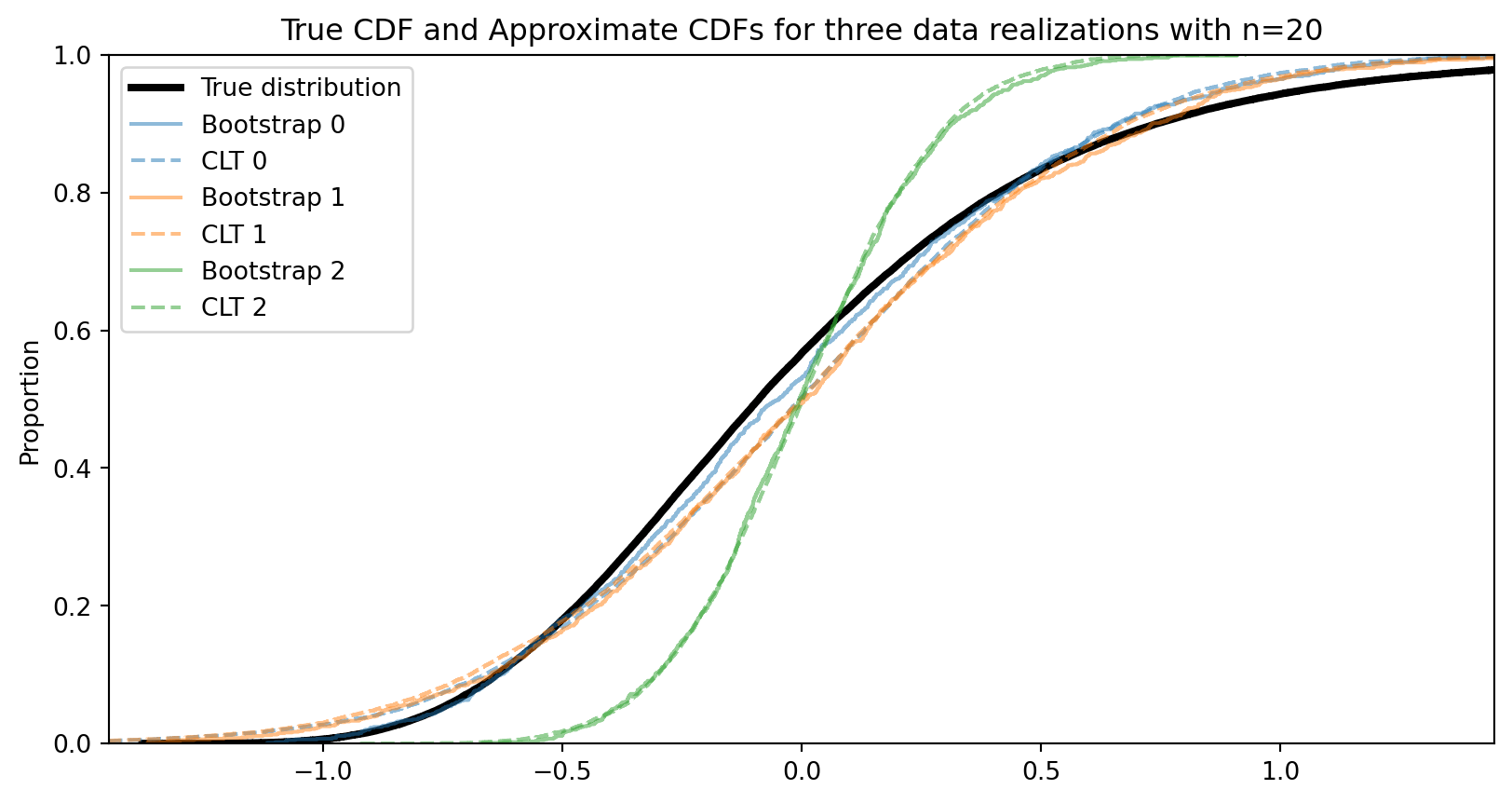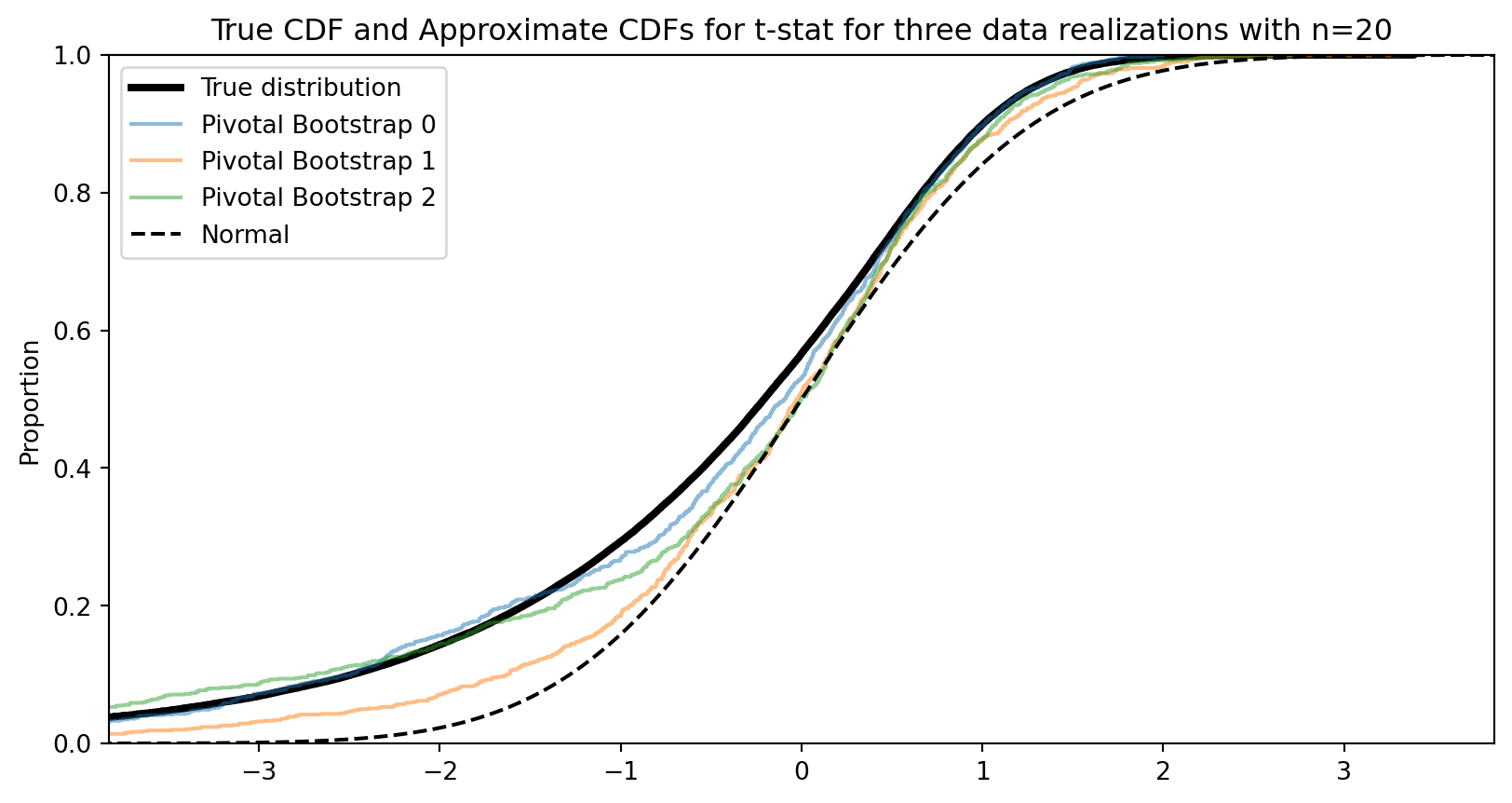
def proportioncisim(phat, n, level=0.95, S=100_000):
se = (phat*(1-phat)/n)**0.5
dp = se/20
p = phat - dp
while (abs(np.random.binomial(n,p, S)/n-p) <= abs((phat-p))).mean() < level :
p = p - dp
if p < 0:
break
plo = p
p = phat + dp
while (abs(np.random.binomial(n,p,S)/n-p) <= abs((phat-p))).mean() < level :
p = p + dp
if p < 0:
break
phi = p
return(plo,phi)
phat = 0.05
n = 100
proportioncisim(phat, 100, level=0.95)(0.024936331074641174, 0.10557596153014372)