Show the code
# !pip install pandas numpy umap-learn matplotlib seaborn plotly nltk spacy scikit-learn scipy transformers torch tqdm --upgrade# !pip install pandas numpy umap-learn matplotlib seaborn plotly nltk spacy scikit-learn scipy transformers torch tqdm --upgrade# import nltk; nltk.download('punkt'); nltk.download('stopwords'); nltk.download('punkt_tab')
# !python -m spacy download en_core_web_sm# This cell loads the necessary libraries for executing the notebook.
import pandas as pd
import numpy as np
import re
import pickle
import umap
import textwrap
import matplotlib.pyplot as plt
from matplotlib.patches import Patch
import seaborn as sns
from IPython.display import HTML
from plotly import io as pio
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from nltk import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
import spacy
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial.distance import cosine
from transformers import AutoTokenizer, AutoModel, pipeline
import torch
import warnings
from collections import defaultdict, Counter
from typing import Dict, Any, UnionMany of you will have, by now, interacted with AI via chatbots. But that format serves to obscure:
In this workshop we will explore, at a very high level, how AI is changing the way historians (and others) can process and analyze text. Specifically, we will:
This workshop provides a high-level overview of these techniques. For readers new to text analysis, the goal is to show that AI is not only a chatbot technology; it is also a set of analytic methods built on decades of NLP and machine-learning research in the social sciences and humanities. For those already familiar with computational text analysis, the goal is to provide an updated view of how recent AI methods are changing the field.
You will not leave this workshop with full mathematical or implementation-level mastery of these techniques; that would require much more time. Instead, our aim is to offer a practical look behind the AI interface, introduce core vocabulary, and build a clearer understanding of what happens when a prompt is submitted and a response is generated.
The 1884 Chinese Regulation Act in British Columbia is widely regarded as one of the most notorious discriminatory provincial laws targeting Chinese immigration. It was challenged and ultimately declared unconstitutional in the 1885 case of R v. Wing Chong by Justice Henry Pering Pellew Crease. Justice Crease found the legislation unconstitutional on economic grounds, arguing that it infringed on federal authority over immigration, trade, commerce, treaty-making, and taxation.
The central figure in the ruling, Henry Pering Pellew Crease, came from a wealthy English military family, and possessed a prestigious law background.
In previous years, students expressed interest in Crease’s opinion on the 1884 Chinese Regulation Act, given that the Act was strongly condemned and ultimately struck down by Crease. However, this seems at odds with Crease’s position on Chinese immigrants.
This raises an interesting question: Did Judge Crease strike down the act because of genuine anti-discrimination concerns, or because he saw the Chinese immigrant labor force as a valuable asset for growing the Canadian economy?
We aim to explore this question by analyzing the language used by Justice Crease in his legal opinions and writings related to Chinese immigrants through Natural Language Processing (NLP) approaches. By examining the text, we hope to uncover insights into his stance.
The workshop also demonstrates how historians can use computational tools to help answer such a research question by showing each step in the research process.
In the end, we will be able to transform the text documents into more intuitive and visually appealing representations, such as a 2D UMAP projection of legal text embeddings by sentence. This can help historians interpret relationships between different texts.
Legal text analysis is a complex task, as legal documents are often lengthy, dense, formal, and filled with specialized terminology. They are also frequently written in neutral or passive voice, making it difficult to discern the author’s opinions or biases. This poses unique challenges for historians and legal scholars and complicates the use of standard natural language processing (NLP) methods.
Mining insights from such texts requires sophisticated techniques to extract meaningful information and identify patterns. We need the technique to be able to:
In this workshop, we address these challenges through a comparison-based approach. We focus on Justice Crease’s texts while comparing them with other legal texts from the same period to better contextualize legal language and argumentative style.
The first subject we will use for comparison is the 1884 Chinese Regulation Act, which was the law that Crease struck down. The second subject we will use for comparison is Justice Matthew Baillie Begbie, who testified alongside Crease in the 1884 Royal Commission on Chinese Immigration.
We use machine learning techniques, specifically text embeddings, to do the following:
This approach demonstrates different techniques historians can use to identify patterns in documents for analysis.
We plan to use 10 digitized texts:
A major challenge in historical text research is source format. Materials are often available only as scans of varying quality from books, reports, and archival documents. Because these are not machine-readable text formats, our first step is to use Optical Character Recognition (OCR) to convert them into analyzable text. We chose this approach because:
Below is a brief overview of early and modern OCR techniques:
After testing several tools, we found that modern, AI-based OCR methods produced the most accurate results for our historical documents.
After OCR, we obtained a .csv file containing the text and metadata of the documents. Note that we removed the direct quotes of the 1884 Chinese Regulation Act in Crease’s ruling, as they don’t reflect his own language. The structure of the data is as follows:
| Column Name | Description |
|---|---|
| filename | Name of the file containing the document text. |
| author | Author of the document (e.g., “Crease”, “Begbie”). |
| type | Document type (e.g., “case”, “report”). |
| text | Full text of the document, which may include OCR errors. |
| act_quote_sentences_removed | Number of quoted sentences removed from the full text. |
Here, we read the .csv file into a pandas DataFrame and display.
# Load the dataset
df = pd.read_csv("data/metadata_cleaned.csv")
df| filename | author | type | text | act_quote_sentences_removed | |
|---|---|---|---|---|---|
| 0 | regina_v_wing_chong.txt | Crease | case | CREASE, J. 1885. REGINA v. WING CHONG. \r\n\r\... | 12 |
| 1 | wong_hoy_woon_v_duncan.txt | Crease | case | CREASE, J.\r\n\r\nWONG HOY WOON v. DUNCAN.\r\n... | 0 |
| 2 | regina_v_mee_wah.txt | Begbie | case | BRITISH COLUMBIA REPORTS.\r\n\r\nREGINA v. MEE... | 0 |
| 3 | regina_v_victoria.txt | Begbie | case | OF BRITISH COLUMBIA.\r\n\r\nREGINA r, CORPORAT... | 0 |
| 4 | quong_wing_v_the_king.txt | Fitzpatrick | case | QUONG WING v. THE KING. CAN. \r\n\r\nSupreme ... | 0 |
| 5 | commission_on_chinese_imigration.txt | Powell | report | On the 4th of July, 1884, the following Commis... | 0 |
| 6 | chapleau_report_resume.txt | Chapleau | report | RESUMÉ.\r\n\r\n1. That Chinese labor is a most... | 0 |
| 7 | crease_commission.txt | Crease | report | The Hon. Mr. Justice CREASE, Judge of the Supr... | 0 |
| 8 | begbie_commission.txt | Begbie | report | Sir MATTHEW BEGBIE, Chief Justice of British C... | 0 |
| 9 | chinese_regulation_act_1884.txt | Others | act | An Act to regulate the Chinese population of B... | 0 |
We are also interested in the length of each document, as it can provide insights into the depth and complexity of the text. Therefore, we create a summary below quantifying the number of characters in each document.
# Summarize the distribution of document lengths
# Create a DataFrame to store the document lengths
doc_lengths = []
# Measure lengths of each document by number of characters
for row in df.iterrows():
text_length = len(row[1]['text'])
doc_lengths.append({'Document': row[1]['filename'], 'Length': text_length})
# Convert to DataFrame and display
doc_lengths_df = pd.DataFrame(doc_lengths)
doc_lengths_df| Document | Length | |
|---|---|---|
| 0 | regina_v_wing_chong.txt | 36819 |
| 1 | wong_hoy_woon_v_duncan.txt | 13912 |
| 2 | regina_v_mee_wah.txt | 25104 |
| 3 | regina_v_victoria.txt | 8252 |
| 4 | quong_wing_v_the_king.txt | 46982 |
| 5 | commission_on_chinese_imigration.txt | 3402 |
| 6 | chapleau_report_resume.txt | 10906 |
| 7 | crease_commission.txt | 30768 |
| 8 | begbie_commission.txt | 41270 |
| 9 | chinese_regulation_act_1884.txt | 12908 |
While computers can process text swiftly, they do not “understand” it in the human sense. Instead, they build mathematical models of language from statistical patterns and structural regularities. These models produce symbolic and continuous representations of words and passages that allow downstream algorithms to detect topics, relationships, and affective signals. However, these representations remain proxies for meaning rather than literal comprehension.
This process typically involves a sequence of steps:
Why this is helpful for social science and humanities research:
The Term Frequency-Inverse Document Frequency (TF-IDF) is a statistical measure that evaluates the importance of a word in a document relative to a collection of documents (corpus). It is one of the earliest and most widely used methods for text analysis. It is essentially a count-based approach that quantifies the importance of words in a document based on their frequency and distribution across multiple documents. TF-IDF works by calculating two components:
For our purpose, we can use TF-IDF to identify the most important words in each document, which can help us understand the key themes and topics discussed in the text. More details on what we are going to do:
# Define the function to preprocess text in a DataFrame column
def preprocess_text(text_string):
"""
Cleans and preprocesses text by:
1. Converting to lowercase
2. Removing punctuation and numbers
3. Tokenizing
4. Removing English stop words
5. Removing words with 4 or fewer characters
"""
# Start with the standard English stop words
stop_words = set(stopwords.words('english'))
# Add custom domain-specific stop words if needed
custom_additions = {'would', 'may', 'act', 'mr', 'sir', 'also', 'upon', 'shall'}
stop_words.update(custom_additions)
# Lowercase and remove non-alphabetic characters
processed_text = text_string.lower()
processed_text = re.sub(r'[^a-z\s]', '', processed_text)
# Tokenize
tokens = processed_text.split()
# Filter out stop words AND short words in a single step
filtered_tokens = [
word for word in tokens
if word not in stop_words and len(word) > 4
]
# Re-join the words into a single string
return " ".join(filtered_tokens)# Apply the function to create the 'processed_text' column
df['processed_text'] = df['text'].apply(preprocess_text)
# Display the first few rows of the processed text
df['processed_text'].head(5)0 crease regina chong certiorarichinese regulati...
1 crease duncan health regulationsvictoria healt...
2 british columbia reports regina begbie constit...
3 british columbia regina corporation victoria p...
4 quong supreme court canada charles fitzpatrick...
Name: processed_text, dtype: object# Perform TF-IDF vectorization on the processed text
# Regroup the DataFrame for better representation
df['group'] = 'Other'
df.loc[df['author'] == 'Crease', 'group'] = 'Crease'
df.loc[df['author'] == 'Begbie', 'group'] = 'Begbie'
df.loc[df['type'] == 'act', 'group'] = 'Regulation Act'
# Load the vectorizer and transform the processed text
# This calculates IDF based on word rarity across ALL individual texts.
vectorizer = TfidfVectorizer(max_features=1000, ngram_range=(1, 3))
tfidf_matrix = vectorizer.fit_transform(df['processed_text'])
# Create a new DataFrame with the TF-IDF scores
feature_names = vectorizer.get_feature_names_out()
tfidf_df = pd.DataFrame(tfidf_matrix.toarray(), columns=feature_names)
# Add the 'group' column to this TF-IDF DataFrame for aggregation
tfidf_df['group'] = df['group'].values
# Group by document group and calculate the mean TF-IDF score for each word
mean_tfidf_by_group = tfidf_df.groupby('group').mean()
# Calculate TF-IDF for the combined corpus ("All") using the same vectorizer
processed_all = " ".join(df['processed_text'])
all_vec = vectorizer.transform([processed_all]).toarray().ravel()
all_series = pd.Series(all_vec, index=feature_names, name='All')
# Add the "All" row to the grouped TF-IDF DataFrame
mean_tfidf_by_group = pd.concat([all_series.to_frame().T, mean_tfidf_by_group], axis=0)
# Collect top words and arrange them into a side-by-side DataFrame
list_of_author_dfs = []
for group_name in ['All', 'Crease', 'Begbie', 'Regulation Act', 'Other']:
if group_name not in mean_tfidf_by_group.index:
# If a group is missing, append an empty frame to keep column alignment
empty_df = pd.DataFrame({group_name: [], f'{group_name}_score': []})
list_of_author_dfs.append(empty_df)
continue
# Get the top 10 terms and scores for the current author/group
top_words = mean_tfidf_by_group.loc[group_name].sort_values(ascending=False).head(10)
# Convert the Series to a DataFrame
top_words_df = top_words.reset_index()
top_words_df.columns = [group_name, f'{group_name}_score']
list_of_author_dfs.append(top_words_df)
# Concatenate the list of DataFrames horizontally
final_wide_df = pd.concat(list_of_author_dfs, axis=1)
# Display the final combined DataFrame (includes "All")
final_wide_df| All | All_score | Crease | Crease_score | Begbie | Begbie_score | Regulation Act | Regulation Act_score | Other | Other_score | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chinese | 0.280587 | chinese | 0.200669 | license | 0.227903 | chinese | 0.441993 | canada | 0.222811 |
| 1 | labor | 0.166864 | labor | 0.168787 | chinamen | 0.149081 | dollars | 0.282347 | chinese | 0.195027 |
| 2 | white | 0.164724 | infected | 0.133485 | licenses | 0.133026 | licence | 0.247053 | legislation | 0.137708 |
| 3 | british | 0.147603 | white | 0.126410 | municipality | 0.113649 | collector | 0.211760 | country | 0.114012 |
| 4 | chinamen | 0.142071 | taxation | 0.103702 | statute | 0.103615 | forfeit | 0.189818 | commissioners | 0.111398 |
| 5 | legislation | 0.141809 | british | 0.096697 | legislature | 0.098166 | lieutenantgovernor | 0.189818 | naturalized | 0.107816 |
| 6 | aliens | 0.140241 | hongkong | 0.095346 | revenue | 0.096980 | person | 0.189591 | great | 0.102256 |
| 7 | taxation | 0.131826 | dominion | 0.092157 | corporation | 0.093326 | possession | 0.188270 | parliament | 0.097569 |
| 8 | naturalized | 0.126216 | health officer | 0.088990 | pawnbrokers | 0.085237 | exceeding | 0.176467 | county | 0.094699 |
| 9 | within | 0.118637 | china | 0.088562 | provincial | 0.084121 | lieutenantgovernor council | 0.166091 | honorable | 0.093340 |
Undoubtedly, the TF-IDF practice on our corpus has identified some interesting patterns, such as:
However, this approach has limitations, as it does not capture the semantic meaning of words or their relationships to each other. For example, it cannot distinguish between “Chinese” as a noun and “Chinese” as an adjective, or between “labor” as a noun and “labor” as a verb. It also does not consider the context in which words are used, which can lead to misinterpretation of their meaning.
With the advancement of machine learning, text embeddings emerged as a more powerful technique for text analysis. It represents words or phrases as dense vectors in a high-dimensional space, capturing semantic relationships between them. This allows for more nuanced understanding of text, enabling tasks like similarity measurement, clustering, and classification.
There are several popular text embedding models, including: - Word2Vec: A neural network-based model that learns word embeddings by predicting context words given a target word (or vice versa). - GloVe: A global vector representation model that learns word embeddings by factorizing the word co-occurrence matrix. - FastText: An extension of Word2Vec that represents words as bags of character n-grams, allowing it to handle out-of-vocabulary words and capture subword information. - BERT: A transformer-based model that generates contextualized embeddings by considering the entire sentence context, allowing it to capture word meanings based on their surrounding words.
In this workshop, we will use a BERT-based model to generate text embeddings for our corpus. nlpaueb/legal-bert-base-uncased is a BERT model pre-trained on English legal texts, including legislation, law cases, and contracts. It is designed to capture the legal language and semantics, making it suitable for our analysis.
However, we must note that the model is not perfect and may still have limitations in understanding the nuances of legal language, especially in historical texts.
While the model itself has the ability to generate word embeddings that capture the semantic meaning of words, we still need to design our own strategy to extract these meanings from our corpus.
In this way, we are not only able to generate word embeddings with contextual meanings over the whole corpus, but also be able to aggregate our corpus into different groups, and generate contextualized word embeddings for each group.
# We will use the Legal-BERT model for this task
tokenizer = AutoTokenizer.from_pretrained('nlpaueb/legal-bert-base-uncased')
model = AutoModel.from_pretrained('nlpaueb/legal-bert-base-uncased').eval() # set the model to evaluation mode
# Define a function to embed words using the tokenizer and model
def embed_words(sentences, tokenizer=tokenizer, model=model, target_words=None,
device=None, max_length=512):
"""
Returns a dictionary {word: mean_embedding}.
Only the mean embedding (float32 numpy array) per word is kept.
"""
if device is None:
try:
device = next(model.parameters()).device
except Exception:
device = torch.device("cpu")
device = torch.device(device)
model.to(device).eval()
target_set = None if target_words is None else set(target_words)
sums = {} # word -> torch.Tensor sum of embeddings
counts = {} # word -> occurrence count
with torch.no_grad():
for sent in sentences:
enc = tokenizer(
sent,
return_tensors="pt",
truncation=True,
max_length=max_length
)
enc = {k: v.to(device) for k, v in enc.items()}
outputs = model(**enc)
hidden = outputs.last_hidden_state.squeeze(0) # (seq_len, hidden)
tokens = tokenizer.convert_ids_to_tokens(enc["input_ids"][0])
i = 0
while i < len(tokens):
tok = tokens[i]
if tok in ("[CLS]", "[SEP]", "[PAD]"):
i += 1
continue
# Gather wordpieces
j = i + 1
piece_embs = [hidden[i]]
word = tok[2:] if tok.startswith("##") else tok
while j < len(tokens) and tokens[j].startswith("##"):
piece_embs.append(hidden[j])
word += tokens[j][2:]
j += 1
if target_set is not None and word not in target_set:
i = j
continue
word_emb = torch.stack(piece_embs, dim=0).mean(dim=0)
if word in sums:
sums[word] += word_emb
counts[word] += 1
else:
sums[word] = word_emb.clone()
counts[word] = 1
i = j
return {w: (sums[w] / counts[w]).cpu().numpy() for w in sums}# Define a function to clean and preprocess text
def clean_text(text):
text = text.lower()
text = re.sub(r'[^\w\s]', '', text) # Remove punctuation
return text.strip()warnings.filterwarnings("ignore")
nlp = spacy.load("en_core_web_sm")
# Group texts to form a single text per group
grouped_texts = df.groupby('group')['text'].apply(lambda x: ' '.join(x)).reset_index()
# Add a row for the combined text of all groups
grouped_texts = pd.concat(
[grouped_texts, pd.DataFrame([{'group': 'All', 'text': ' '.join(df['text'])}])],
ignore_index=True
)
# Create new columns for word and sentence tokens
grouped_texts['word_tokens'] = grouped_texts['text'].apply(lambda x: word_tokenize(clean_text(x)))
# Sentence tokenization using spaCy
grouped_texts['sentence_tokens'] = grouped_texts['text'].apply(lambda x: [sent.text for sent in nlp(x).sents])
# Apply clean_text to the sentence tokens
grouped_texts['sentence_tokens'] = grouped_texts['sentence_tokens'].apply(
lambda x: [clean_text(sent) for sent in x]
)# # Embed the words in each group
# grouped_texts['word_embeddings'] = grouped_texts['sentence_tokens'].apply(
# lambda x: embed_words(x)
# )
# # Save the grouped_texts DataFrame to a pkl file for future use
# grouped_texts.to_pickle("data/word_embeddings.pkl")# Compute the number of unique words in each group
grouped_texts['num_unique_words'] = grouped_texts['word_tokens'].apply(lambda x: len(set(x)))
grouped_texts.head()| group | text | word_tokens | sentence_tokens | num_unique_words | |
|---|---|---|---|---|---|
| 0 | Begbie | BRITISH COLUMBIA REPORTS.\r\n\r\nREGINA v. MEE... | [british, columbia, reports, regina, v, mee, w... | [british columbia reports, regina v mee wah be... | 2622 |
| 1 | Crease | CREASE, J. 1885. REGINA v. WING CHONG. \r\n\r\... | [crease, j, 1885, regina, v, wing, chong, 14th... | [crease j 1885, regina v wing chong, 14th 15t... | 2654 |
| 2 | Other | QUONG WING v. THE KING. CAN. \r\n\r\nSupreme ... | [quong, wing, v, the, king, can, supreme, cour... | [quong wing v the king, can, supreme court of ... | 1906 |
| 3 | Regulation Act | An Act to regulate the Chinese population of B... | [an, act, to, regulate, the, chinese, populati... | [an act to regulate the chinese population of ... | 576 |
| 4 | All | CREASE, J. 1885. REGINA v. WING CHONG. \r\n\r\... | [crease, j, 1885, regina, v, wing, chong, 14th... | [crease j 1885, regina v wing chong, 14th 15t... | 4849 |
# Load the grouped_texts DataFrame from CSV
grouped_texts = pd.read_pickle("data/word_embeddings.pkl")We created word embeddings of all tokens in each group, respectively. The word embeddings are stored in a dictionary format, where each key is a word and the value is its corresponding embedding vector.
It is clear that the word embeddings of the same word in different groups are different, which reflects the contextualized meaning of the word in each group.
# Display the word embedding of Chinese for the whole corpus
chinese_embedding = grouped_texts[grouped_texts['group'] == 'All']['word_embeddings'].values[0].get('chinese')
# Display first 20 dimensions for brevity
print(f"First 20 Dimensions of Word Embedding for 'Chinese' in the Full Corpus:\n {chinese_embedding[:20]}\n")
print(f"Total Dimensions of Word Embedding for 'Chinese': {len(chinese_embedding)}\n")First 20 Dimensions of Word Embedding for 'Chinese' in the Full Corpus:
[ 0.12668514 0.26626247 0.06976263 0.03987848 0.3198149 0.12648065
0.1179221 0.25096533 -0.24571839 -0.09690513 0.06757622 0.46853873
0.00413261 -0.08175131 -0.42389032 0.25379455 0.11806588 -0.129208
-0.60333675 0.4287366 ]
Total Dimensions of Word Embedding for 'Chinese': 768
# Display the word embedding of Chinese in Crease's text
crease_embeddings = grouped_texts[grouped_texts['group'] == 'Crease']['word_embeddings'].values[0]
# Display first 20 dimensions for brevity
print(f"First 20 Dimensions of Word Embeddings for 'Chinese' in Crease's Text:\n{crease_embeddings.get('chinese')[:20]}\n")
print(f"Total Dimensions of Word Embeddings for 'Chinese' in Crease's Text: {len(crease_embeddings.get('chinese'))}\n")First 20 Dimensions of Word Embeddings for 'Chinese' in Crease's Text:
[ 0.1207148 0.31710652 0.04701388 0.07962938 0.30281344 0.09768455
0.14006759 0.2546475 -0.22537379 -0.09438673 0.0616338 0.49788
0.00510495 -0.07701945 -0.4433001 0.3088299 0.0834146 -0.12817031
-0.56065226 0.4199316 ]
Total Dimensions of Word Embeddings for 'Chinese' in Crease's Text: 768
begbie_embeddings = grouped_texts[grouped_texts['group'] == 'Begbie']['word_embeddings'].values[0]
# Display first 20 dimensions for brevity
print(f"First 20 Dimensions of Word Embeddings for 'Chinese' in Begbie's Text:\n{begbie_embeddings.get('chinese')[:20]}\n")
print(f"Total Dimensions of Word Embeddings for 'Chinese' in Begbie's Text: {len(begbie_embeddings.get('chinese'))}\n")First 20 Dimensions of Word Embeddings for 'Chinese' in Begbie's Text:
[ 0.13345422 0.28776637 0.01769559 -0.01827072 0.30239815 0.16497923
0.01982685 0.31021848 -0.2716136 0.00533469 0.05232281 0.4485962
-0.04535438 -0.05225528 -0.52643675 0.36453673 0.16012253 -0.15775643
-0.59051466 0.37558916]
Total Dimensions of Word Embeddings for 'Chinese' in Begbie's Text: 768
Another important aspect of word embeddings is the ability to measure the similarity between words based on their embeddings. This can be done using cosine similarity, which calculates the cosine of the angle between two vectors in the embedding space. Cosine similarity ranges from -1 to 1, where:
This allows us to identify related words and concepts based on their embeddings, enabling us to explore the semantic relationships between words in our corpus. More importantly, it allows us to measure similarity not only between words, but also between sentences, paragraphs, and entire documents, as long as they are represented as vectors in the same embedding space.
The math behind cosine similarity is as follows: \[ \text{cosine similarity}(a, b) = \frac{a \cdot b}{||a|| \cdot ||b||} \] Where \(a\) and \(b\) are the embedding vectors of the two words, and \(||a||\) and \(||b||\) are their Euclidean norms (vector lengths).
Focusing on the word “Chinese”, we can calculate its cosine similarity with other words in the same group to identify related terms. This can help us understand how the word is used in different contexts and how it relates to other concepts. Here, we will list out the top 10 most similar words to “Chinese” in each group, along with their cosine similarity scores.
Note: All words are converted to lowercase.
# Compute top-10 most similar words to target for EVERY group (including "All")
target = "chinese"
top_n = 10
all_results = []
# Iterate through each group and compute similarities
for _, grp_row in grouped_texts.iterrows():
group = grp_row['group']
emb_dict = grp_row['word_embeddings']
if target not in emb_dict:
continue
target_vec = emb_dict[target]
sims = []
for w, vec in emb_dict.items():
if w == target:
continue
try:
sim = 1 - cosine(target_vec, vec)
except Exception:
continue
sims.append((w, sim))
sims_sorted = sorted(sims, key=lambda x: x[1], reverse=True)[:top_n]
for rank, (w, sim) in enumerate(sims_sorted, 1):
all_results.append({'group': group, 'rank': rank, 'word': w, 'similarity': sim}) # Use :4f for better readability
similar_words_df = pd.DataFrame(all_results)
# Display the first few rows of the DataFrame with similar words
sims_wide = similar_words_df.pivot(index='rank', columns='group', values='similarity')
words_wide = similar_words_df.pivot(index='rank', columns='group', values='word')
# Combine with a tidy multi-level column index:
wide_combined = pd.concat({'word': words_wide, 'similarity': sims_wide}, axis=1)
wide_combined = (
wide_combined.swaplevel(0,1, axis=1)
.sort_index(axis=1, level=0)
)
wide_combined # Display| group | All | Begbie | Crease | Other | Regulation Act | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| similarity | word | similarity | word | similarity | word | similarity | word | similarity | word | |
| rank | ||||||||||
| 1 | 0.882441 | chinamen | 0.876610 | china | 0.884398 | chinamen | 0.877303 | china | 0.759336 | immigrant |
| 2 | 0.879673 | chinaman | 0.869450 | chinamen | 0.876641 | chinaman | 0.876505 | chinamen | 0.744862 | employer |
| 3 | 0.878318 | china | 0.866370 | chinaman | 0.866081 | china | 0.870729 | chinaman | 0.740853 | whites |
| 4 | 0.833719 | japanese | 0.816941 | whites | 0.857200 | white | 0.815160 | orientals | 0.739350 | native |
| 5 | 0.833196 | white | 0.811970 | white | 0.846658 | aliens | 0.812049 | aliens | 0.734877 | person |
| 6 | 0.833098 | immigrants | 0.798483 | english | 0.816191 | confederation | 0.810886 | alien | 0.726807 | yards |
| 7 | 0.831805 | immigrant | 0.797803 | europeans | 0.816176 | coolies | 0.810220 | immigrants | 0.710742 | emergency |
| 8 | 0.830698 | whites | 0.796832 | universal | 0.815357 | immigrants | 0.804137 | asiatic | 0.708795 | licence |
| 9 | 0.822064 | aliens | 0.791045 | canton | 0.814902 | sweet | 0.803130 | provincial | 0.708284 | found |
| 10 | 0.820433 | alien | 0.789463 | provincial | 0.813782 | japanese | 0.803034 | oriental | 0.708163 | race |
In comparison to generating word embeddings, modeling stance of each text is more challenging, as it requires us to capture the author’s position on a specific issue or topic. Oftentimes, the stance is not explicitly stated in the text, but rather implied through the language used.
There is not a universal optimum for stance modeling, as it depends on the specific context and the author’s perspective. However, we can use a combination of techniques to create focused embeddings that capture the stance of each text. The strategy we used is as follows:
This approach thus allows us to create focused embeddings that capture the stance of each text focusing on specific keywords or phrases. The sentence is used as the basic unit of analysis here, but larger chunks of text can also be used if needed.
In the end, we will store the lists of embeddings in a dictionary format, where each key is the author and the value is a list of embeddings for each text authored by that author.
def embed_text(
text,
focus_token=None,
window=10,
pooling="mean", # "mean" (default), "max", or "min"
tokenizer=tokenizer,
model=model):
# Get stopwords for filtering
stop_words = set(stopwords.words('english'))
# Run the model once
inputs = tokenizer(text, return_tensors="pt", truncation=True)
with torch.no_grad():
outputs = model(**inputs)
hidden = outputs.last_hidden_state.squeeze(0)
if focus_token is None:
return hidden[0].cpu().numpy()
# Normalize to list
keywords = (
[focus_token] if isinstance(focus_token, str)
else focus_token
)
# Pre-tokenize each keyword to its subtoken ids
kw_token_ids = {
kw: tokenizer.convert_tokens_to_ids(tokenizer.tokenize(kw))
for kw in keywords
}
input_ids = inputs["input_ids"].squeeze(0).tolist()
tokens = tokenizer.convert_ids_to_tokens(input_ids)
spans = [] # list of (start, end) index pairs
# find every match of every keyword
for kw, sub_ids in kw_token_ids.items():
L = len(sub_ids)
for i in range(len(input_ids) - L + 1):
if input_ids[i:i+L] == sub_ids:
spans.append((i, i+L))
if not spans:
# fallback on CLS vector
return hidden[0].cpu().numpy()
# For each span, grab the window around it
vecs = []
for (start, end) in spans:
lo = max(1, start - window)
hi = min(hidden.size(0), end + window)
# Filter out stopwords from the window
non_stop_indices = [i for i in range(lo, hi)
if tokens[i] not in stop_words and not tokens[i].startswith('##')]
# If all tokens are stopwords, use the original window
if not non_stop_indices:
span_vec = hidden[lo:hi]
else:
span_vec = hidden[non_stop_indices]
if pooling == "mean":
pooled = span_vec.mean(dim=0)
elif pooling == "max":
pooled = span_vec.max(dim=0).values
elif pooling == "min":
pooled = span_vec.min(dim=0).values
else:
raise ValueError(f"Unknown pooling method: {pooling}")
vecs.append(pooled.cpu().numpy())
# Average across all spans
return np.mean(np.stack(vecs, axis=0), axis=0)crease_cases = df[(df['author'] == 'Crease') & (df['type'] == 'case')]['text'].tolist()
begbie_cases = df[(df['author'] == 'Begbie') & (df['type'] == 'case')]['text'].tolist()
act_1884 = df[df['type'] == 'act']['text'].tolist()
act_dict = {
'Crease': crease_cases,
'Begbie': begbie_cases,
'Act 1884': act_1884}act_snippets = {}
keywords = ["Chinese", "China", "Chinaman", "Chinamen",
"immigrant", "immigrants", "alien", "aliens",
"immigration"]
for auth, texts in act_dict.items():
snippets = []
for txt in texts:
# Sentence tokenize using Spacy
sentence = [sent.text for sent in nlp(txt).sents]
for sent in sentence:
if any(keyword in sent for keyword in keywords):
snippets.append(sent)
act_snippets[auth] = snippets# Investigate the length of the snippets
n_snippet = {auth: len(snippets) for auth, snippets in act_snippets.items()}
print("Snippet size by author:")
for auth, num in n_snippet.items():
print(f"{auth}: {num}")Snippet size by author:
Crease: 83
Begbie: 18
Act 1884: 24# # Create embeddings
# embeddings_dict = {'Crease': [], 'Begbie': [], 'Act 1884': []}
# for auth, snippets in act_snippets.items():
# for snip in snippets:
# v = embed_text(snip, focus_token=keywords, window=15)
# embeddings_dict[auth].append(v)
# # Save the embeddings dictionary to a pickle file
# with open("data/case_snippet_embeddings.pkl", "wb") as f:
# pickle.dump(embeddings_dict, f)# read in the embeddings dictionary
with open("data/case_snippet_embeddings.pkl", "rb") as f:
embeddings_dict = pickle.load(f)Just like word embeddings, cosine similarity can also be used to measure the stance similarity between texts. The interpretation of cosine similarity in this context is similar to that of word embeddings, where a higher cosine similarity indicates a stronger alignment in stance between two texts.
With sentence being the basic unit of analysis, we can calculate the overall cosine similarity between each pair of authors’ texts in various ways, but here we will focus on two of them:
Note that similarity scores are not deterministic, as they depend on the specific texts and the context in which the keywords are used. However, they can provide valuable insights into the stance of each author and how it relates to other authors’ positions. This reinforces the idea that stance is not a fixed attribute, but rather a dynamic and context-dependent aspect of language.
# Compute the pairwise cosine similarity
mean_crease = np.mean(embeddings_dict["Crease"], axis=0, keepdims=True)
mean_begbie = np.mean(embeddings_dict["Begbie"], axis=0, keepdims=True)
mean_act_1884 = np.mean(embeddings_dict["Act 1884"], axis=0, keepdims=True)
sim_crease_begbie = cosine_similarity(mean_crease, mean_begbie)[0, 0]
sim_crease_act_1884 = cosine_similarity(mean_crease, mean_act_1884)[0, 0]
sim_begbie_act_1884 = cosine_similarity(mean_begbie, mean_act_1884)[0, 0]
print(f"Cosine similarity between mean Crease and mean Begbie: {sim_crease_begbie:.4f}")
print(f"Cosine similarity between mean Crease and mean Act 1884: {sim_crease_act_1884:.4f}")
print(f"Cosine similarity between mean Begbie and mean Act 1884: {sim_begbie_act_1884:.4f}")Cosine similarity between mean Crease and mean Begbie: 0.9866
Cosine similarity between mean Crease and mean Act 1884: 0.9670
Cosine similarity between mean Begbie and mean Act 1884: 0.9643# Extract embeddings for Crease, Begbie and the Act 1884
crease_embeddings = embeddings_dict["Crease"]
begbie_embeddings = embeddings_dict["Begbie"]
act_1884_embeddings = embeddings_dict["Act 1884"]
# Define a function to compute mean cosine similarity
def mean_cosine_similarity(embeddings1, embeddings2):
similarities = [
1 - cosine(e1, e2)
for e1 in embeddings1
for e2 in embeddings2
]
return sum(similarities) / len(similarities)
# Extract embeddings
crease_emb = embeddings_dict["Crease"]
begbie_emb = embeddings_dict["Begbie"]
act_1884_emb = embeddings_dict["Act 1884"]
# Compute mean similarities
crease_begbie_sim = mean_cosine_similarity(crease_emb, begbie_emb)
crease_act_sim = mean_cosine_similarity(crease_emb, act_1884_emb)
begbie_act_sim = mean_cosine_similarity(begbie_emb, act_1884_emb)
# Output
print(f"Mean cosine similarity between Crease and Begbie embeddings: {crease_begbie_sim:.4f}")
print(f"Mean cosine similarity between Crease and Act 1884 embeddings: {crease_act_sim:.4f}")
print(f"Mean cosine similarity between Begbie and Act 1884 embeddings: {begbie_act_sim:.4f}")Mean cosine similarity between Crease and Begbie embeddings: 0.8326
Mean cosine similarity between Crease and Act 1884 embeddings: 0.8174
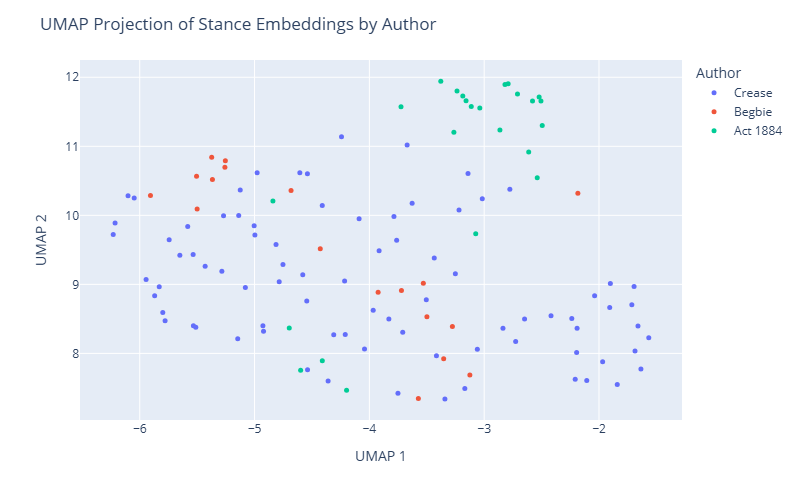
Mean cosine similarity between Begbie and Act 1884 embeddings: 0.8166While the embeddings themselves are high-dimensional vectors (in our case, 768-dimensional), we can visualize them in a lower-dimensional space (e.g., 2D or 3D) using dimensionality reduction techniques such as UMAP (Uniform Manifold Approximation and Projection).
UMAP is a dimensionality reduction technique that projects high-dimensional embeddings into a 2D space while preserving local structure, making it ideal for visualizing our embeddings.
Using Plotly Express, we create an interactive scatter plot where each point represents a text snippet, colored by author, with hover functionality to display the corresponding sentence. This visualization highlights clusters and relationships between snippets, offering insights into semantic similarities across authors.
# Set seed for umap reproducibility
all_vecs = np.vstack(embeddings_dict["Crease"] + embeddings_dict["Begbie"] + embeddings_dict["Act 1884"])
labels = (["Crease"] * len(embeddings_dict["Crease"])) + (["Begbie"] * len(embeddings_dict["Begbie"])) + (['Act 1884'] * len(embeddings_dict["Act 1884"]))
reducer = umap.UMAP(n_neighbors=15, min_dist=0.1, random_state=42)
proj = reducer.fit_transform(all_vecs)
def wrap_text(text, width=60):
return '<br>'.join(textwrap.wrap(text, width=width))pio.renderers.default = "plotly_mimetype+notebook_connected"
umap_df = pd.DataFrame(proj, columns=['UMAP 1', 'UMAP 2'])
umap_df['Author'] = labels
umap_df['Text'] = [snip for auth in act_snippets for snip in act_snippets[auth]]
umap_df['Text'] = umap_df['Text'].apply(lambda t: wrap_text(t, width=60))
fig = px.scatter(umap_df, x='UMAP 1', y='UMAP 2',
color='Author', hover_data=['Text'],
width=800, height=500 )
fig.update_traces(marker=dict(size=5))
fig.update_layout(title='UMAP Projection of Stance Embeddings by Author')
fig.show()The stance embeddings ultimately serve as analytical tools to support our text analysis objectives.
Here, we will examine the top 10 sentences with the highest stance similarity to the mean stance of each author.
This approach allows us to delve deeper into the texts, uncovering how the language used aligns with the calculated average stance and providing richer insights into the authors’ positions on the issue of Chinese immigrants.
# Print out the 10 most similar embedding sentences to Crease's mean embedding
crease_similarity_df = pd.DataFrame(columns=['Author', 'Text', 'Similarity Score'])
# Iterate through the embeddings and their corresponding sentences
for auth, snippets in act_snippets.items():
for snippet, emb in zip(snippets, embeddings_dict[auth]):
similarity = cosine_similarity(emb.reshape(1, -1), mean_crease)[0][0]
crease_similarity_df.loc[len(crease_similarity_df)] = [auth, snippet, similarity]
# Sort by similarity score
crease_sorted_similarity = crease_similarity_df.sort_values(by='Similarity Score', ascending=False)
print("Top 10 most similar sentences to Crease's mean embedding:\n")
for _, row in crease_sorted_similarity.head(10).iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nSentence: {wrapped_para}\nSimilarity Score: {row['Similarity Score']:.4f}\n")Top 10 most similar sentences to Crease's mean embedding:
Author: Crease
Sentence: Another statute (of 1878), "An Act to provide for the better collection of taxes from Chinese,"
which contained several of the stringent provisions which I have described in this Act, such as a
special tax specially recoverable by summary and unusual remedies from the Chinese alone, in British
Columbia, and enforced by fine and imprisonment and other penal clauses, came before this Court, and
in a most conscientious and exhaustive judgment of Mr. Justice Gray, of 23rd September, 1878, in the
case of Tai Sing v. Maguire, was declared unconstitutional and ultra vires the Local Legislature, as
interfering with aliens and trade and commerce—matters reserved exclusively under the 81st section
of the B. N. A. Act to the Dominion.
Similarity Score: 0.9598
Author: Crease
Sentence: In the case of the Chinese treaties, they were forced at the point of the bayonet on China, to
obtain a right for us to enter China, and in return for a similar permission to us, full permission
was given for the Chinese to trade and reside in British dominions everywhere.
Similarity Score: 0.9572
Author: Crease
Sentence: The California cases (see The People v. Naglee, 1 Cal. 232) decided a differential tax might be
imposed on foreign miners; and though a later case (Lin Sing v. Washburn, 20 Cal. 334) had decided a
special tax could not be imposed on Chinese, a most celebrated Judge, Mr. Justice Field (since
elevated to the Federal bench), dissented, and had pointed out that according to federal decisions
the State might impose special taxation on alien residents, provided the impost was not levied
against foreigners landing in the country.
Similarity Score: 0.9532
Author: Crease
Sentence: The basis, then, of our enquiry must be: Is this Chinese Regulation Act of 1884—rather the parts of
it objected to—within the limit of subjects and area of section 92, or does it exceed those limits
in which it is supreme, and interfere with aliens, trade and commerce in such a manner as to
encroach on section 91 or any of its sub-sections?
Similarity Score: 0.9525
Author: Crease
Sentence: The Act is found associated with another Act now disallowed, the express object of which is to
prevent the Chinese altogether from coming to this country, and the principle "noscitur a sociis" is
kept up by the preamble of the present Act, which describes the Chinese in terms which, I venture to
think, have never before in any other country found a place in an Act of Parliament.
Similarity Score: 0.9514
Author: Crease
Sentence: So far, I have dealt with the Act on its own merits; but if we consider it in juxtaposition to the
Dominion Act recently passed restricting the Chinese throughout all Canada, its illegality becomes
transparent; for in passing that Act against the Chinese the Dominion has spoken by the highest
authority which it possesses—its own Parliament.
Similarity Score: 0.9492
Author: Crease
Sentence: Opponents to the Act might as well contend the exclusion of the Chinese from the franchise, and
barring them from acquiring lands, was illegal.
Similarity Score: 0.9491
Author: Crease
Sentence: He reviewed the legislation against Chinese since confederation, contending it was levelled against
a particular race of aliens and, therefore, beyond provincial control, per *Gwynne*, J., in
*Citizens Insurance Co. v. Parsons*, 4 S. C. R., at p. 346.
Similarity Score: 0.9489
Author: Crease
Sentence: His duty was, if he considered the Empress of China came from "an infected locality," at once to go
on board the suspected vessel and make his examination and inspection on board the vessel (as
Section 32 says), "before any luggage, freight or other thing is landed or allowed to be landed.
Similarity Score: 0.9481
Author: Crease
Sentence: And again, "A tax imposed by the law on these persons for the mere right to reside here, is an
appropriate and effective means to discourage the immigration of the Chinese into the State.
Similarity Score: 0.9478
# Print out the 10 most similar embedding sentences to Begbie's mean embedding
begbie_similarity_df = pd.DataFrame(columns=['Author', 'Text', 'Similarity Score'])
# Iterate through the embeddings and their corresponding sentences
for auth, snippets in act_snippets.items():
for snippet, emb in zip(snippets, embeddings_dict[auth]):
similarity = cosine_similarity(emb.reshape(1, -1), mean_begbie)[0][0]
begbie_similarity_df.loc[len(begbie_similarity_df)] = [auth, snippet, similarity]
# Sort by similarity score
begbie_sorted_similarity = begbie_similarity_df.sort_values(by='Similarity Score', ascending=False)
print("Top 10 most similar sentences to Begbie's mean embedding:\n")
for _, row in begbie_sorted_similarity.head(10).iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nSentence: {wrapped_para}\nSimilarity Score: {row['Similarity Score']:.4f}\n")Top 10 most similar sentences to Begbie's mean embedding:
Author: Begbie
Sentence: Indeed if no restriction whatever be placed on the word " other" in that section; if the Provincial
Legislature can insist upon imposing licenses upon everything and upon every act of life, and tax
each licensee at any moment they please, there would be a very simple way of excluding every
Chinaman from the Province, by imposing a universal tax, not limited to any nationality, of one or
two thousand dollars per annum for a license to Judgment.
Similarity Score: 0.9539
Author: Begbie
Sentence: Statutes were by their title and preamble expressly aimed at Chinamen by name; that this
distinction also renders inapplicable all the United States' cases cited; that this enactment is
quite general extending to all laundries without exception and we must not look beyond the words of
the enactment to enquire what its object was; that there is in fact one laundry in Victoria not
conducted by Chinamen on which the tax will fall with equal force so that it is impossible to say
that Chinamen are hereby exclusively selected for taxation; the circumstance that they are chiefly
affected being a mere coincidence; that the bylaw only imposes $100.00 per annum, keeping far within
the limit of $150.00 permitted by the Statute; that the tax clearly is calculated to procuring
additional Municipal revenue and that no other object is hinted at.
Similarity Score: 0.9534
Author: Crease
Sentence: The California cases (see The People v. Naglee, 1 Cal. 232) decided a differential tax might be
imposed on foreign miners; and though a later case (Lin Sing v. Washburn, 20 Cal. 334) had decided a
special tax could not be imposed on Chinese, a most celebrated Judge, Mr. Justice Field (since
elevated to the Federal bench), dissented, and had pointed out that according to federal decisions
the State might impose special taxation on alien residents, provided the impost was not levied
against foreigners landing in the country.
Similarity Score: 0.9534
Author: Begbie
Sentence: no other description of labour taxed at all ; (2nd) this description of labour practically quite
abandoned to Chinamen alone ; (3rd) this description of labour taxed at fifteen times the rate
permitted to be levied on any retail shop ; (4th) that a preliminary Provincial Act has declared
Chinamen incapable of the franchise which they formerly exercised.
Similarity Score: 0.9529
Author: Crease
Sentence: Another statute (of 1878), "An Act to provide for the better collection of taxes from Chinese,"
which contained several of the stringent provisions which I have described in this Act, such as a
special tax specially recoverable by summary and unusual remedies from the Chinese alone, in British
Columbia, and enforced by fine and imprisonment and other penal clauses, came before this Court, and
in a most conscientious and exhaustive judgment of Mr. Justice Gray, of 23rd September, 1878, in the
case of Tai Sing v. Maguire, was declared unconstitutional and ultra vires the Local Legislature, as
interfering with aliens and trade and commerce—matters reserved exclusively under the 81st section
of the B. N. A. Act to the Dominion.
Similarity Score: 0.9525
Author: Begbie
Sentence: The appellants' contention that the clause is merely intended to hamper or expel Chinamen is much
strengthened by considering the amount of the tax sanctioned, which is $150.00 per annum, whereas
the limit sanctioned by the Legislature in the case of any retail shop, however extensive or
lucrative its business, is only $10.00 per annum.
Similarity Score: 0.9473
Author: Begbie
Sentence: In the French colony of Cayenne, the Town Council recently handicapped the superior capacities of
the Chinaman by imposing on merchants of that empire an extra tax of $300 per annum, deeming it also
expedient to handicap English and German traders by a surtax of $200 on them.
Similarity Score: 0.9453
Author: Crease
Sentence: The basis, then, of our enquiry must be: Is this Chinese Regulation Act of 1884—rather the parts of
it objected to—within the limit of subjects and area of section 92, or does it exceed those limits
in which it is supreme, and interfere with aliens, trade and commerce in such a manner as to
encroach on section 91 or any of its sub-sections?
Similarity Score: 0.9424
Author: Crease
Sentence: And again, "A tax imposed by the law on these persons for the mere right to reside here, is an
appropriate and effective means to discourage the immigration of the Chinese into the State.
Similarity Score: 0.9421
Author: Crease
Sentence: The Act is found associated with another Act now disallowed, the express object of which is to
prevent the Chinese altogether from coming to this country, and the principle "noscitur a sociis" is
kept up by the preamble of the present Act, which describes the Chinese in terms which, I venture to
think, have never before in any other country found a place in an Act of Parliament.
Similarity Score: 0.9420
# Print out the 10 most similar embedding sentences to the Regulation Act's mean embedding
regulation_similarity_df = pd.DataFrame(columns=['Author', 'Text', 'Similarity Score'])
# Iterate through the embeddings and their corresponding sentences
for auth, snippets in act_snippets.items():
for snippet, emb in zip(snippets, embeddings_dict[auth]):
similarity = cosine_similarity(emb.reshape(1, -1), mean_act_1884)[0][0]
regulation_similarity_df.loc[len(regulation_similarity_df)] = [auth, snippet, similarity]
# Sort by similarity score
regulation_sorted_similarity = regulation_similarity_df.sort_values(by='Similarity Score', ascending=False)
print("Top 10 most similar sentences to the Regulation Act's mean embedding:\n")
for _, row in regulation_sorted_similarity.head(10).iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nSentence: {wrapped_para}\nSimilarity Score: {row['Similarity Score']:.4f}\n")Top 10 most similar sentences to the Regulation Act's mean embedding:
Author: Act 1884
Sentence: In case any employer of Chinese fails to deliver to the Collector the list mentioned in the
preceding section, when required so to do, or knowingly states anything falsely therein, such
employer shall, on complaint of the Collector and upon conviction before a Justice of the Peace
having jurisdiction within the district wherein such employer carries on his business, forfeit and
pay a fine not exceeding one hundred dollars for every Chinese in his employ, to be recovered by
distress of the goods and chattels of such employer failing to pay the same, or in lieu thereof
shall be liable to imprisonment for a period not less than one month and not exceeding two calendar
months.
Similarity Score: 0.9566
Author: Act 1884
Sentence: It shall be unlawful for any person to employ any Chinese who has not in his possession the licence
required by this Act, and any person guilty of an infraction of the provisions of this section shall
forfeit and pay a fine not exceeding fifty dollars for every Chinese so employed.
Similarity Score: 0.9538
Author: Act 1884
Sentence: The sum payable by a Chinese for a free miner’s certificate shall be fifteen dollars for each year
during which the same is to be in force instead of five dollars, as by the present mining laws
provided, and no free miner’s certificate shall hereafter be issued to any Chinese except upon
payment of the said sum of fifteen dollars. 15.
Similarity Score: 0.9492
Author: Act 1884
Sentence: Any Chinese who shall be found mining for gold and precious metals, or following the ordinary
occupation of a free miner, whether on his own account or for others, without having in his
possession a free miner’s certificate, lawfully issued to him subsequently to the passage of this
Act, and any person who shall employ any Chinese in and about gold mining who has not in his
possession such a certificate, shall forfeit and pay a sum not exceeding thirty dollars.
Similarity Score: 0.9486
Author: Crease
Sentence: Another statute (of 1878), "An Act to provide for the better collection of taxes from Chinese,"
which contained several of the stringent provisions which I have described in this Act, such as a
special tax specially recoverable by summary and unusual remedies from the Chinese alone, in British
Columbia, and enforced by fine and imprisonment and other penal clauses, came before this Court, and
in a most conscientious and exhaustive judgment of Mr. Justice Gray, of 23rd September, 1878, in the
case of Tai Sing v. Maguire, was declared unconstitutional and ultra vires the Local Legislature, as
interfering with aliens and trade and commerce—matters reserved exclusively under the 81st section
of the B. N. A. Act to the Dominion.
Similarity Score: 0.9454
Author: Act 1884
Sentence: The Toll Collector at any and every toll gate which may exist in the Province from time to time,
shall, before allowing any Chinese to pass through any toll gate, demand from such Chinese the
production of his licence, and, until the same is produced, such Chinese shall not be allowed to
proceed through the toll gate.
Similarity Score: 0.9437
Author: Act 1884
Sentence: The Collector may, by himself or his agent, levy the amount of the licence from any Chinese not
being in lawful possession of a licence, with costs, by distress of his goods and chattels, or of
any goods and chattels which may be in the possession of the delinquent, or which may be upon or in
any premises (whether the goods of the delinquent or not) for the time being in the possession or
occupation of such delinquent Chinese, and for the purposes of this section premises shall be deemed
to be in the possession or occupation of any Chinese when it can be shewn to the satisfaction of the
tribunal having cognizance of the matter— (a.) That such Chinese habitually frequents such
premises with the assent of the owner. (b.) That he is the owner or one of the owners of the
premises, or has control either alone or jointly with another or others of such premises or some
part thereof.
Similarity Score: 0.9424
Author: Act 1884
Sentence: Every employer of Chinese shall furnish to the Collector, when requested by him so to do, from time
to time, a list of all Chinese in his employ, or indirectly employed by him; but no such statement
shall bind the Collector, nor shall excuse him from making due enquiry to ascertain its correctness.
Similarity Score: 0.9418
Author: Act 1884
Sentence: From and after the passage of this Act there shall be payable and paid by every Chinese in British
Columbia, above the age of fourteen years, unto and for the use of Her Majesty, Her heirs and
successors, the sum of ten dollars, and thereafter on the 1st day of June in each and every year
there shall be likewise payable and paid by such Chinese person a further sum of ten dollars.
Similarity Score: 0.9393
Author: Act 1884
Sentence: The term "Chinese" wherever used in this Act shall mean any native of the Chinese Empire or its
dependencies not born of British parents, and shall include any person of the Chinese race.
Similarity Score: 0.9393
final_wide_df| All | All_score | Crease | Crease_score | Begbie | Begbie_score | Regulation Act | Regulation Act_score | Other | Other_score | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | chinese | 0.280587 | chinese | 0.200669 | license | 0.227903 | chinese | 0.441993 | canada | 0.222811 |
| 1 | labor | 0.166864 | labor | 0.168787 | chinamen | 0.149081 | dollars | 0.282347 | chinese | 0.195027 |
| 2 | white | 0.164724 | infected | 0.133485 | licenses | 0.133026 | licence | 0.247053 | legislation | 0.137708 |
| 3 | british | 0.147603 | white | 0.126410 | municipality | 0.113649 | collector | 0.211760 | country | 0.114012 |
| 4 | chinamen | 0.142071 | taxation | 0.103702 | statute | 0.103615 | forfeit | 0.189818 | commissioners | 0.111398 |
| 5 | legislation | 0.141809 | british | 0.096697 | legislature | 0.098166 | lieutenantgovernor | 0.189818 | naturalized | 0.107816 |
| 6 | aliens | 0.140241 | hongkong | 0.095346 | revenue | 0.096980 | person | 0.189591 | great | 0.102256 |
| 7 | taxation | 0.131826 | dominion | 0.092157 | corporation | 0.093326 | possession | 0.188270 | parliament | 0.097569 |
| 8 | naturalized | 0.126216 | health officer | 0.088990 | pawnbrokers | 0.085237 | exceeding | 0.176467 | county | 0.094699 |
| 9 | within | 0.118637 | china | 0.088562 | provincial | 0.084121 | lieutenantgovernor council | 0.166091 | honorable | 0.093340 |
In the TF-IDF analysis, we observed that the word “Chinese” was a prominent term across all groups, indicating its centrality to the discussions in all texts. Following the word “Chinese”, we also noticed that “labor”, “white”, “legislation”, and “taxation” were all significant terms reflected in all texts. This makes us wonder: How do these topics relate to each other, and how do they align with the stances of different authors?
In natural language processing, topic modeling is a technique used to identify and extract topics from a collection of documents. It involves analyzing the words and phrases in the text to identify patterns and themes that can be grouped together into topics. Oftentimes, topic modeling is performed using unsupervised learning algorithms such as Latent Dirichlet Allocation (LDA). However, these methods may not be suitable for our corpus, as they require a large amount of text data and may not capture the nuances of legal language.
Therefore, we will use a different approach to explore the topics in our corpus, by leveraging the word embeddings we have already generated. The strategy we will use is as follows:
# Define our target "topics"
target_words = ["labor", "legislation", "license", "taxation"]
# Find most similar words to the keywords using the "All" group embeddings
all_emb = grouped_texts.loc[grouped_texts['group'] == 'All', 'word_embeddings'].values
if len(all_emb) == 0:
raise ValueError("No 'All' group found in grouped_texts")
all_emb = all_emb[0]
top_n = 10
results = {}
for target in target_words:
target_vec = all_emb.get(target)
if target_vec is None:
# fill with NaN if target missing
results[target] = [np.nan] * top_n
continue
sims = []
for w, vec in all_emb.items():
if w == target:
continue
try:
sim = 1 - cosine(target_vec, vec)
except Exception:
continue
sims.append((w, sim))
sims_sorted = sorted(sims, key=lambda x: x[1], reverse=True)[:top_n]
results[target] = [w for w, _ in sims_sorted]
# Create DataFrame with targets as columns and ranks as rows
similar_words_df = pd.DataFrame(results)
similar_words_df| labor | legislation | license | taxation | |
|---|---|---|---|---|
| 0 | labour | statute | licence | tax |
| 1 | wages | ordinance | licenses | taxes |
| 2 | laborers | parliament | licensee | legislation |
| 3 | work | act | licensea | taxability |
| 4 | laboring | legislature | licensing | discrimination |
| 5 | employment | law | certificate | taxing |
| 6 | workmen | legislatures | permission | taxed |
| 7 | capital | enactment | bylaw | rates |
| 8 | industry | enactments | licences | imposition |
| 9 | service | clauses | receipt | discriminating |
# Create anchors for the topics
def create_anchor(topic, similar_df=similar_words_df, top_n=10):
t = topic
# collect words: topic + top_n similar words
similar_words = similar_df[t].astype(str).tolist()[:top_n]
words = [t] + [w.lower() for w in similar_words]
# deduplicate while preserving order
seen = set()
uniq_words = []
for w in words:
if w not in seen:
seen.add(w)
uniq_words.append(w)
# embed each word and average
vecs = []
for w in uniq_words:
emb = embed_text(w)
vecs.append(emb)
return np.mean(np.stack(vecs, axis=0), axis=0)# Create anchors for the topics
labor_anchor = create_anchor("labor")
legislation_anchor = create_anchor("legislation")
license_anchor = create_anchor("license")
taxation_anchor = create_anchor("taxation")
# Create a DataFrame to hold the anchors
anchors_df = pd.DataFrame({
'Topic': ['labor', 'legislation', 'license', 'taxation'],
'Anchor Vector': [labor_anchor, legislation_anchor, license_anchor, taxation_anchor]
})
anchors_df| Topic | Anchor Vector | |
|---|---|---|
| 0 | labor | [-0.2501059, 0.11760723, 0.4144639, -0.1028304... |
| 1 | legislation | [-0.105285525, -0.07808617, 0.336891, 0.061590... |
| 2 | license | [-0.13483904, -0.035231713, 0.53634995, -0.104... |
| 3 | taxation | [-0.024709284, -0.010419514, 0.3513746, -0.129... |
# Calculate the cosine similarity between each anchor and the mean embeddings of Crease, Begbie, and the Act 1884
# Visualize the results as a box plot
def calculate_similarity(anchor, embeddings):
return cosine_similarity(anchor.reshape(1, -1), embeddings).flatten()
# Create a DataFrame to hold the similarity scores
similarity_scores = {
'Author': [],
'Topic': [],
'Text': [],
'Similarity Score': []
}
for topic in anchors_df['Topic']:
anchor_vector = anchors_df.loc[anchors_df['Topic'] == topic, 'Anchor Vector'].values[0]
for author in ['Crease', 'Begbie', 'Act 1884']:
emb_list = embeddings_dict.get(author, [])
texts = act_snippets.get(author, [])
if len(emb_list) == 0:
continue
embeddings = np.vstack(emb_list)
sim_scores = calculate_similarity(anchor_vector, embeddings)
for idx, score in enumerate(sim_scores):
similarity_scores['Author'].append(author)
similarity_scores['Topic'].append(topic)
similarity_scores['Text'].append(texts[idx] if idx < len(texts) else "")
similarity_scores['Similarity Score'].append(float(score))
# Convert to DataFrame
similarity_df = pd.DataFrame(similarity_scores)# prepare authors and topics
preferred_order = ['Crease', 'Begbie', 'Act 1884']
authors = [a for a in preferred_order if a in similarity_df['Author'].unique()]
topics = list(similarity_df['Topic'].unique())[:4]
# Color Blind friendly palette
author_palette = sns.color_palette("colorblind", n_colors=len(authors))
sns.set(style="whitegrid", context="notebook")
fig, axes = plt.subplots(2, 2, figsize=(8, 6), sharey=False)
for i in range(4):
ax = axes.flat[i]
if i < len(topics):
topic = topics[i]
df_t = similarity_df[similarity_df['Topic'] == topic]
# draw boxplot
sns.boxplot(
data=df_t,
x='Author',
y='Similarity Score',
order=authors,
palette=author_palette,
width=0.6,
fliersize=0,
ax=ax,
boxprops=dict(linewidth=0.9),
medianprops=dict(linewidth=1.1, color='black'),
whiskerprops=dict(linewidth=0.9),
capprops=dict(linewidth=0.9)
)
# compute per-author means and overlay them
means = df_t.groupby('Author')['Similarity Score'].mean().reindex(authors)
x_positions = list(range(len(authors)))
# plot white diamond with black edge so it stands out on colored boxes
ax.scatter(x_positions, means.values, marker='D', s=60,
facecolors='white', edgecolors='black', zorder=10)
# robust y-limits
vals = df_t['Similarity Score'].dropna()
if len(vals) == 0:
ymin, ymax = -1.0, 1.0
else:
q1 = vals.quantile(0.25)
q3 = vals.quantile(0.75)
iqr = q3 - q1
if iqr == 0:
whisker_low = float(vals.min())
whisker_high = float(vals.max())
else:
whisker_low = float(q1 - 1.5 * iqr)
whisker_high = float(q3 + 1.5 * iqr)
span = max(whisker_high - whisker_low, 1e-6)
pad = max(span * 0.08, 0.03)
ymin = max(-1.0, whisker_low - pad)
ymax = min(1.0, whisker_high + pad)
if ymin >= ymax:
mid = float(vals.median())
ymin = max(-1.0, mid - 0.05)
ymax = min(1.0, mid + 0.05)
ax.set_ylim(ymin, ymax)
ax.set_title(f"Topic: {topic}", fontsize=12, weight='semibold')
ax.set_xlabel('')
ax.set_ylabel('Cosine Similarity' if i % 2 == 0 else '')
ax.axhline(0.0, color='grey', linestyle='--', linewidth=0.8, alpha=0.6)
ax.tick_params(axis='x', rotation=0, labelsize=10)
ax.tick_params(axis='y', labelsize=9)
for spine in ax.spines.values():
spine.set_linewidth(0.8)
sns.despine(ax=ax, trim=True, left=False, bottom=False)
else:
ax.set_visible(False)
# Single legend for authors
legend_handles = [Patch(facecolor=author_palette[idx], label=authors[idx]) for idx in range(len(authors))]
fig.legend(handles=legend_handles, title='Author', loc='upper right', frameon=True)
plt.tight_layout(rect=[0, 0, 0.95, 0.96])
fig.suptitle('Topic Similarity by Author\n(Mean Labeled by Diamond)', fontsize=14, y=0.99)
plt.show()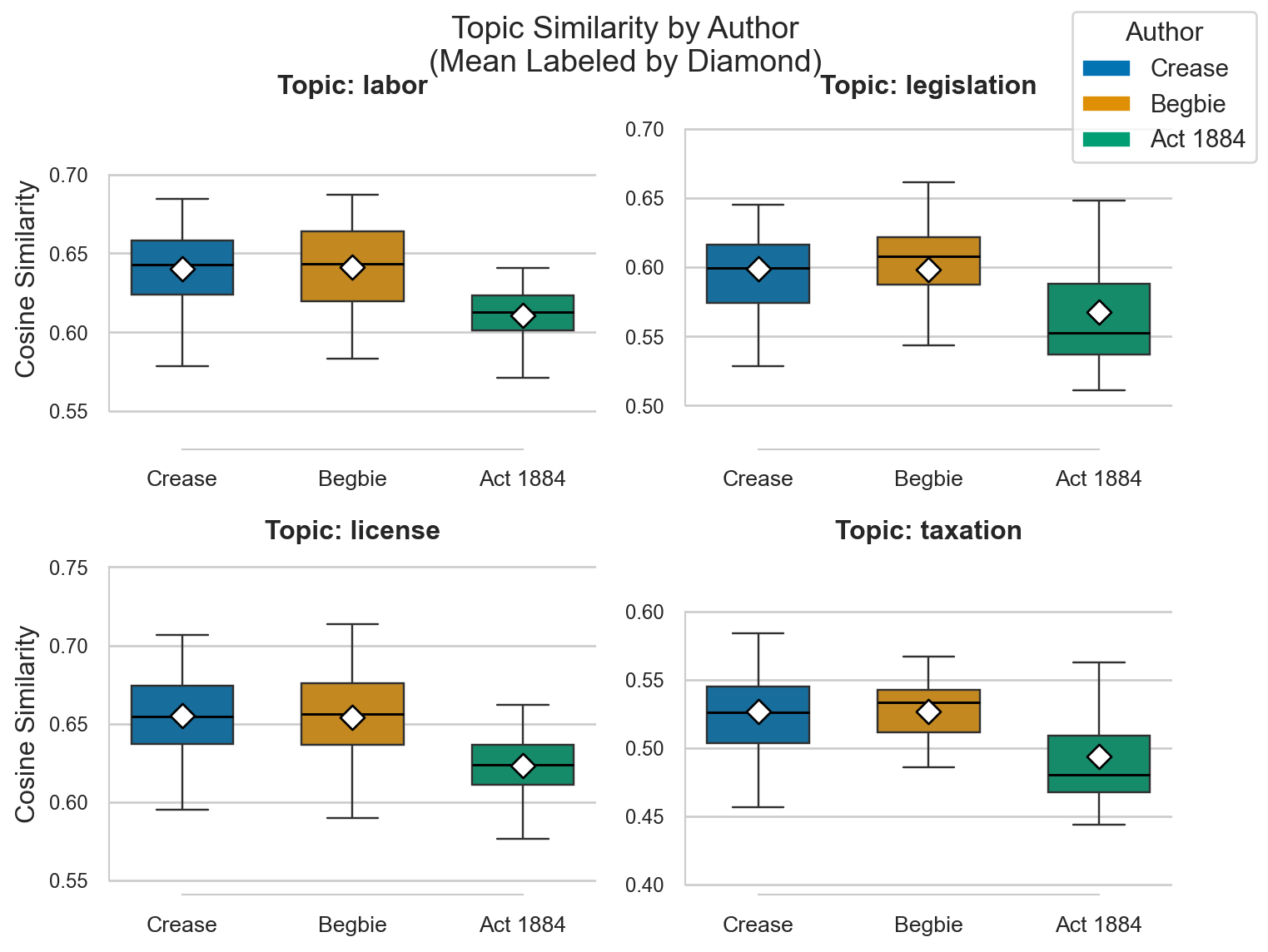
Another powerful technique for text analysis is zero-shot classification, which allows us to classify text into predefined categories without requiring labeled training data, with the help of large language models (LLMs). This approach is particularly useful when we have a limited amount of labeled data or when the categories are not well-defined.
In addition to classifying text into specific categories, zero-shot classification can also be used to evaluate the stance of a text toward a particular issue or topic by calculating model-assigned probabilities over categories. These probabilities sum to 1 for each input under softmax normalization, but they should be interpreted as relative model preference scores rather than calibrated confidence. In this workshop, we mainly focus on this stance-evaluation use case.
We use the Hugging Face Transformers library to implement zero-shot classification with MoritzLaurer/DeBERTa-v3-large-mnli-fever-anli-ling-wanli (as specified in the code below). This model is trained on natural language inference (NLI) tasks and learns to score whether a premise-hypothesis pair is in entailment, neutral, or contradiction relation. In zero-shot classification, our candidate labels are converted into hypotheses, and model scores over these hypotheses are used to infer stance.
The key steps in our zero-shot classification process are as follows:
# Create the full snippets dictionary
act_1884_full = " ".join(act_1884)
crease_cases_full = " ".join(crease_cases)
begbie_cases_full = " ".join(begbie_cases)
full_cases = {"Crease": crease_cases_full, "Begbie": begbie_cases_full, "Act 1884": act_1884_full}# We create a dictionary to hold the full snippets for each author
full_snippets = {}
for author, text in full_cases.items():
# Tokenize using Spacy
sentence = [sent.text for sent in nlp(text).sents]
snippets = []
for sent in sentence:
if len(sent) > 30: # Filter out short and meaningless sentences created by tokenization
snippets.append(sent)
full_snippets[author] = snippets# Create a DataFrame to display snippet size by author
snippet_sizes = [{'Author': auth, 'Snippet Count': len(snippets)} for auth, snippets in full_snippets.items()]
snippet_sizes_df = pd.DataFrame(snippet_sizes)
# Display the DataFrame
print(snippet_sizes_df) Author Snippet Count
0 Crease 262
1 Begbie 193
2 Act 1884 40To ensure that the zero-shot classification results are meaningful, we carefully treat the candidate labels as prompts that guide the model’s understanding of the stance categories. This allows us to leverage the model’s ability to generalize and adapt to new tasks without requiring extensive retraining or fine-tuning. Here, we will use the following candidate labels:
However, we must note that this is also a major limitation of the zero-shot classification approach, as it relies on the quality and relevance of the candidate labels to the text being classified. If the labels are not well-defined or do not accurately reflect the stance categories, the classification results may be misleading or inaccurate. This is particularly important when working with historical texts, where the language and context may differ significantly from modern usage. Therefore, it is essential to carefully select and define the candidate labels to ensure that they accurately reflect the stance categories we are interested in.
# Create pipeline for zero-shot classification with error handling and efficiency improvements
warnings.filterwarnings("ignore")
zero_shot = pipeline(
"zero-shot-classification",
model="MoritzLaurer/DeBERTa-v3-large-mnli-fever-anli-ling-wanli",
tokenizer="MoritzLaurer/DeBERTa-v3-large-mnli-fever-anli-ling-wanli",
hypothesis_template="In this snippet of a historical legal text, the author {}.",
device=0 if torch.cuda.is_available() else -1 # Use GPU if available
)
# Simplified and clearer labels for better classification
labels = [
"advocates for equal legal treatment of Chinese immigrants compared to white or European settlers, opposing racial discrimination",
"describes or retells the status or treatment of Chinese immigrants without expressing support or opposition to racial inequality, is unrelated to Chinese immigrants, or cannot be classified as either",
"justifies or reinforces unequal legal treatment of Chinese immigrants relative to white or European settlers, supporting racially discriminatory policies"
]
def get_scores(snippet, max_length=512):
# Ensure snippet is not empty and is reasonable length
if not snippet or len(snippet.strip()) < 10:
return {label: 0.33 for label in labels} # Return neutral scores for empty/short text
# Truncate if too long to avoid token limit issues
if len(snippet) > max_length * 4:
snippet = snippet[:max_length * 4]
# Run classification
out = zero_shot(snippet, candidate_labels=labels, truncation=True, max_length=max_length)
# Create score dictionary
score_dict = dict(zip(out["labels"], out["scores"]))
# Ensure all labels are present
for label in labels:
if label not in score_dict:
score_dict[label] = 0.0
return score_dictWARNING:tensorflow:From D:\Users\alexr\anaconda3\Lib\site-packages\tf_keras\src\losses.py:2976: The name tf.losses.sparse_softmax_cross_entropy is deprecated. Please use tf.compat.v1.losses.sparse_softmax_cross_entropy instead.
Device set to use cpuWe can test the zero-shot classification pipeline on a sample text to see how it works. For example, we can use a paragraph from Sir Chapleau’s report to the Royal Commission on Chinese immigration:
That assuming Chinese immigrants of the laboring class will persist in retaining their present characteristics of Asiatic life, where these are strikingly peculiar and distinct from western, and that the influx will continue to increase, this immigration should be dealt with by Parliament ; but no legislation should be such as would give a shock to great interests and enterprises established before any probability that Parliament would interfere with that immigration arose. Questions of vested rights might come up, and these ought to be carefully considered before action is taken.
# Define the snippet
chapleau_snippet = "That assuming Chinese immigrants of the laboring class will persist in retaining their present characteristics of Asiatic life, where these are strikingly peculiar and distinct from western, and that the influx will continue to increase, this immigration should be dealt with by Parliament; but no legislation should be such as would give a shock to great interests and enterprises established before any probability that Parliament would interfere with that immigration arose. Questions of vested rights might come up, and these ought to be carefully considered before action is taken."
# Get the scores for the snippet
chapleau_scores = get_scores(chapleau_snippet)
# Display the scores
print("Classification Scores for Chapleau's Snippet:")
for label, score in chapleau_scores.items():
print(f"{score:.4f}: {label}")Classification Scores for Chapleau's Snippet:
0.9752: justifies or reinforces unequal legal treatment of Chinese immigrants relative to white or European settlers, supporting racially discriminatory policies
0.0219: describes or retells the status or treatment of Chinese immigrants without expressing support or opposition to racial inequality, is unrelated to Chinese immigrants, or cannot be classified as either
0.0028: advocates for equal legal treatment of Chinese immigrants compared to white or European settlers, opposing racial discriminationAnother limitation of the zero-shot classification is that the number of tokens in the text is limited, which means that we cannot classify the entire text at once if it exceeds the token limit. To avoid exceeding the token limit, we can split the text into smaller chunks, such as sentences or windows of text, and classify each chunk separately.
The sentence approach is to classify each sentence in the text separately, which allows us to capture the stance of each sentence and its relationship to the overall text. This approach is particularly useful when the text is long or complex, as it allows us to analyze the stance of each sentence in isolation.
However, it has limitations in understanding the overall stance of the text, as it does not consider the context in which the sentences are used and therefore may capture too much variation in the stance of the text.
# # Run zero-shot classification on the snippets from the Chinese Regulation Act 1884
# act_scores = {}
# for auth, snippets in full_snippets.items():
# scores = []
# for snip in snippets:
# score = get_scores(snip)
# scores.append(score)
# act_scores[auth] = scores
# rows = []
# for auth, snippets in full_snippets.items():
# for snip, score_dict in zip(snippets, act_scores[auth]):
# row = {
# "Author": auth,
# "Text": snip,
# "Pro": score_dict[labels[0]],
# "Neutral": score_dict[labels[1]],
# "Cons": score_dict[labels[2]]
# }
# rows.append(row)
# # Create DataFrame to store the scores
# df_scores = pd.DataFrame(rows)
# # Save the DataFrame to a CSV file
# df_scores.to_csv("data/zero_shot_sentence_scores.csv", index=False)# Read the saved DataFrame
df_scores = pd.read_csv("data/zero_shot_sentence_scores.csv")
# Print out the top 10 sentences with the highest "Pro" scores
top_pro_sentences = df_scores.nlargest(10, 'Pro')
print("\nTop 10 sentences with the highest 'Pro' scores:\n")
for _, row in top_pro_sentences.iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nSentence: {wrapped_para}\nPro Score: {row['Pro']:.4f}\n")
Top 10 sentences with the highest 'Pro' scores:
Author: Begbie
Sentence: Rep. 354; Baker v. Portland, 5 Law 750; Teburcio Parrott's case, coram SAWYER and HOFFMAN, J.J.,
1880, and the Quene ordinance case, coram FIELD and SAWYER, J.J., 1879; the two latter cases
published in a separate pamphlet form, in which the opinions of Mr. Justices FIELD, HOFFMAN, SAWYER
and DEADY and other Judges whom they cite, all confirm this, that a State, or Provincial law
imposing special disabilities or unequal burdens on Chinamen is unconstitutional and void.
Pro Score: 0.9983
Author: Crease
Sentence: The treaty of 25th August, 1842, *Hertslet*, Vol. 6, ratified 26th June, 1843, p. 221, and Lord
Elgin's treaty of October, 1860, authenticated copies of which were produced in Court, secure to
Chinese coming into British dominions the same "full security for persons and property as subjects
of Her Majesty."
Pro Score: 0.9938
Author: Crease
Sentence: The treaties I have quoted between Great Britain and China, binding on the Dominion and on us in
British Columbia, secure to the Chinese, just as the treaties between Great Britain and other
foreign countries secure to other foreigners, the same rights in regard to the equality of taxation
which I have described as being enjoyed by citizens of this country.
Pro Score: 0.9821
Author: Crease
Sentence: In another California case, *In re Tiburcio Parrott*, it is laid down that if the apparent object of
a statute is under a pretense of the exercise of constitutional powers to drive Chinese away, the
end sought to be obtained being unlawful, the statute is void.
Pro Score: 0.9675
Author: Begbie
Sentence: It is not competent to the Provincial Legislature, or to a municipality, to deprive, generally,
particular nationalities or individuals of the capacity to take out municipal trade licenses ; e.
g., a Chinaman has a right to apply for a pawnbroker's license.
Pro Score: 0.9569
Author: Begbie
Sentence: (5) If it appears that a tax is not bona fide within the purpose provided for, but is imposed with
the real purpose of discriminating against a class, it is not within the justification of the
enabling statute, and, on the facts, the tax in question was intended not for the purpose of raising
a revenue, but as a restriction on the Chinese.
Pro Score: 0.8986
Author: Crease
Sentence: The same provisions that apply to Chinese may be made to apply also to Americans, Frenchmen,
Germans, or any other foreigners.
Pro Score: 0.8445
Author: Crease
Sentence: *Cooley* stated that irrespective of constitutional limitation a particular class of citizens could
not be burdened for the advantage of others—*Cooley's Constitutional Limitations*, p. 635.
Pro Score: 0.8311
Author: Begbie
Sentence: If the object of the Provincial Statute be as alleged, viz., Feb. 3. to subject Chinamen to
exceptional disadvantages it is clearly unconstitutional.
Pro Score: 0.8281
Author: Crease
Sentence: The plaintiff and other Chinamen similarly situated obtained a writ of Habeas Corpus, upon which
they were discharged from this custody.
Pro Score: 0.8127
# Print out the top 10 sentences with the highest "Cons" scores
top_cons_sentences = df_scores.nlargest(10, 'Cons')
print("\nTop 10 sentences with the highest 'Cons' scores:\n")
for _, row in top_cons_sentences.iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nSentence: {wrapped_para}\nCons Score: {row['Cons']:.4f}\n")
Top 10 sentences with the highest 'Cons' scores:
Author: Act 1884
Sentence: In case any employer of Chinese fails to deliver to the Collector the list mentioned in the
preceding section, when required so to do, or knowingly states anything falsely therein, such
employer shall, on complaint of the Collector and upon conviction before a Justice of the Peace
having jurisdiction within the district wherein such employer carries on his business, forfeit and
pay a fine not exceeding one hundred dollars for every Chinese in his employ, to be recovered by
distress of the goods and chattels of such employer failing to pay the same, or in lieu thereof
shall be liable to imprisonment for a period not less than one month and not exceeding two calendar
months.
Cons Score: 0.9975
Author: Crease
Sentence: The provisions of the Act I have given somewhat in extenso bear out that view, and the concurrent
and previous local legislation bear out the same impression, for on the same day as this Act was
passed, another Act was passed, the very object of which was plainly stated to be "to prevent the
immigration" of Chinese."
Cons Score: 0.9973
Author: Begbie
Sentence: Indeed if no restriction whatever be placed on the word " other" in that section; if the Provincial
Legislature can insist upon imposing licenses upon everything and upon every act of life, and tax
each licensee at any moment they please, there would be a very simple way of excluding every
Chinaman from the Province, by imposing a universal tax, not limited to any nationality, of one or
two thousand dollars per annum for a license to Judgment.
Cons Score: 0.9968
Author: Begbie
Sentence: Statutes were by their title and preamble expressly aimed at Chinamen by name; that this
distinction also renders inapplicable all the United States' cases cited; that this enactment is
quite general extending to all laundries without exception and we must not look beyond the words of
the enactment to enquire what its object was; that there is in fact one laundry in Victoria not
conducted by Chinamen on which the tax will fall with equal force so that it is impossible to say
that Chinamen are hereby exclusively selected for taxation; the circumstance that they are chiefly
affected being a mere coincidence; that the bylaw only imposes $100.00 per annum, keeping far within
the limit of $150.00 permitted by the Statute; that the tax clearly is calculated to procuring
additional Municipal revenue and that no other object is hinted at.
Cons Score: 0.9964
Author: Begbie
Sentence: The test is whether on the whole statute the Legislature can fairly be held to have said : "Let us
impose a tax in order to raise a revenue, though perhaps it may fall on Chinamen," or " let us
impose this tax in order to fall on Chinamen, though perhaps it will raise no revenue."
Cons Score: 0.9959
Author: Crease
Sentence: Its object, though not apparent on the face of the Act, was to prevent Chinese coming into the
Province and drive out those who had already come.
Cons Score: 0.9954
Author: Crease
Sentence: Now this assumes, as Dr. Davie assumed, that Hongkong, although a British port and subject to
quarantine regulations, was (which includes the time of the steamer's departure) and is a cradle of
small pox, and that every ship coming thence to Victoria, especially with Chinese on board, should
be subject to the most searching examination, and the drastic treatment I have described.
Cons Score: 0.9953
Author: Act 1884
Sentence: Any Chinese who shall be found within the Province not having in his possession a licence issued
under the provisions of this Act, lawfully issued to him, shall on conviction thereof forfeit and
pay a sum not exceeding forty dollars.
Cons Score: 0.9950
Author: Crease
Sentence: But it should be understood that these exceptional powers are a great trust placed in the hands of
the Health Officer to meet such cases as I have described, and at all times to be administered with
firmness, judgment and discretion—not under any fear of infection unwarranted by the facts of the
case which may enter into the mind of the Health Officer, or to be carried out by carting off en
masse to the suspect station all who hail from China or Hongkong without examination or enquiry.
Cons Score: 0.9949
Author: Crease
Sentence: The Act is found associated with another Act now disallowed, the express object of which is to
prevent the Chinese altogether from coming to this country, and the principle "noscitur a sociis" is
kept up by the preamble of the present Act, which describes the Chinese in terms which, I venture to
think, have never before in any other country found a place in an Act of Parliament.
Cons Score: 0.9945
# Group by author and calculate mean scores
mean_scores = df_scores.groupby("Author")[["Pro", "Neutral", "Cons"]].mean()
median_scores = df_scores.groupby("Author")[["Pro", "Neutral", "Cons"]].median()
print("Mean scores by author:")
print(mean_scores)
print("\nMedian scores by author:")
print(median_scores)Mean scores by author:
Pro Neutral Cons
Author
Act 1884 0.077513 0.047532 0.874955
Begbie 0.226490 0.129033 0.644477
Crease 0.174504 0.108616 0.716880
Median scores by author:
Pro Neutral Cons
Author
Act 1884 0.025958 0.011471 0.966877
Begbie 0.216141 0.133395 0.632564
Crease 0.143930 0.100281 0.748224df_scores['Wrapped Text'] = df_scores['Text'].apply(lambda t: wrap_text(t, width = 50))
fig = px.scatter(
df_scores,
x="Pro",
y="Cons",
color="Author",
hover_data=["Wrapped Text"],
title="Pros vs Cons Scores by Author",
width=800,
height=600
)
fig.update_traces(marker=dict(size=5))
fig.show()In comparison to the sentence approach, the window approach is to classify larger chunks of text that contain multiple sentences with an overlapping context between windows. This allows us to capture the stance of the text in a more holistic way, while still being able to classify each window separately.
The limitation of this approach is that it may not capture the nuances of each sentence, as it treats the window containing multiple sentences as a single unit. However, it allows us to capture the overall stance of the text while still being able to classify each window separately.
Here, we define the function to split the text into overlapping windows of a specified size (maximum number of tokens) with a certain overlap (stride that overlap between consecutive windows). We then apply the zero-shot classification pipeline to each window and average the results to obtain the final classification for the entire text.
# Define a function to chunk text into overlapping windows
def chunk_into_windows(text, max_tokens=512, stride=128):
# Break into sentences first for cleaner boundaries
sents = sent_tokenize(text)
windows = []
current = ""
for sent in sents:
# Tentative window if we add this sentence
cand = current + " " + sent if current else sent
# Count tokens
n_tokens = len(tokenizer.encode(cand, add_special_tokens=False))
if n_tokens <= max_tokens:
current = cand
else:
# finalize current window, then start new from overlapping tail
windows.append(current)
# keep the stride tokens from the end of the current window
tail_ids = tokenizer.encode(current, add_special_tokens=False)[-stride:]
tail_text = tokenizer.decode(tail_ids)
current = tail_text + " " + sent
if current:
windows.append(current)
return windows# # Run classification per author
# rows = []
# for author, text in full_cases.items():
# windows = chunk_into_windows(text, max_tokens=256, stride=64)
# # classify each window
# for win in windows:
# out = zero_shot(win, candidate_labels=labels, truncation=True, max_length=256)
# # Extract scores and labels
# score_dict = dict(zip(out["labels"], out["scores"]))
# rows.append({
# "Author": author,
# "Text": win,
# "Pro": score_dict[labels[0]],
# "Neutral": score_dict[labels[1]],
# "Cons": score_dict[labels[2]]
# })
# all_scores = pd.DataFrame(rows)
# # Save the DataFrame to a CSV file
# all_scores.to_csv("data/zero_shot_windowed_scores.csv", index=False)# Read the saved DataFrame
all_scores = pd.read_csv("data/zero_shot_windowed_scores.csv")
# Print out the top 5 windows with the highest "Pro" scores
top_pro_windows = all_scores.nlargest(5, 'Pro')
print("\nTop 5 windows with the highest 'Pro' scores:\n")
for _, row in top_pro_windows.iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nWindow: {wrapped_para}\nPro Score: {row['Pro']:.4f}\n")
Top 5 windows with the highest 'Pro' scores:
Author: Begbie
Window: ##9 ; the two latter cases published in a separate pamphlet form, in which the opinions of mr.
justices field, hoffman, sawyer and deady and other judges whom they cite, all confirm this, that a
state, or provincial law imposing special disabilities or unequal burdens on chinamen is
unconstitutional and void. In British Columbia such a law if it impose a tax labours under the
additional infirmity that a licence tax for any other purpose with any other object, than merely
raising a revenue, is beyond the power of the Provincial Legislature to impose. Mr. Yates, for the
Corporation, urged that this Statute is very different from the Statutes condemned by Mr. Justice
1886. Feb. 3. CREASE in Wing Chong's case and by Mr. GRAY in Tai Lung's case; those.
Pro Score: 0.9993
Author: Begbie
Window: of the act. 1886. if the object of the provincial statute be as alleged, viz., feb. 3. to subject
chinamen to exceptional disadvantages it is clearly unconstitutional. that point has been so held in
this court by mr. justice gray in tai lung's case, reported appx. G. to the report of the recent
Chinese Conmission, p. 379, and by Mr. Justice CREASE in Wing Chong's case, 1 B.C.R. Pt. II, 150,
both these learned Judges fortifying their opinions by numerous decisions and arguments of Judges in
the United States' Courts. Those decisions are not binding on us here; and indeed are partly founded
on the Constitution of the United States and its relation to the several States, which in many
respects differ from the Constitution and the relation between the Dominion and the Provinces. But
the Judges in those foreign Courts have had a much longer and more varied experience on these topics
than ourselves; their institutions are closely analogous in many Judgment. respects, though, it is
true, contrasted in others to our own.
Pro Score: 0.9973
Author: Begbie
Window: from the constitution and the relation between the dominion and the provinces. but the judges in
those foreign courts have had a much longer and more varied experience on these topics than
ourselves ; their institutions are closely analogous in many judgment. respects, though, it is true,
contrasted in others to our own. And their opinions and reasonings being also founded on
international law, and, I take the liberty of saying, on natural equity and common sense, they are
entitled to great weight beyond the limits of their own jurisdiction. I shall only mention Lee Sing
v. Washburn, 20 Cal. Rep. 354; Baker v. Portland, 5 Law 750; Teburcio Parrott's case, coram SAWYER
and HOFFMAN, J.J., 1880, and the Quene ordinance case, coram FIELD and SAWYER, J.J., 1879; the two
latter cases published in a separate pamphlet form, in which the opinions of Mr. Justices FIELD,
HOFFMAN, SAWYER and DEADY and other Judges whom they cite, all confirm this, that a State, or
Provincial law imposing special disabilities or unequal burdens on Chinamen is unconstitutional and
void.
Pro Score: 0.9925
Author: Crease
Window: , or that the plaintiff had been " exposed to infection. " held, that the facts were insufficient to
justify the action of the health officer under the by - law. remarks on the duties of health
officers. statement action, claiming damages, for trespass. the facts fully appear from the head
note and from the judgment. H. Dallas Helmcken, for the plaintiff. W. J. Taylor, for the defendant.
Judgment. CREASE, J.: This was a test action to try whether Chinamen have the same rights as other
foreigners in landing here on their advent from China. The occasion was the arrival of the Empress
of China at the Outer Wharf, which is within the city limits of Victoria, on the 1st day of May,
1894, from China and Hongkong. The action is one nominally rather than really, for damages against
Dr. George Duncan, the Health Officer of the City of Victoria, on account of an alleged excess of
duty in despatching en masse, without examination or enquiry, a number of Chinamen out to the
suspect station at Ross Bay, there to be disinfected and scrubbed.
Pro Score: 0.9755
Author: Crease
Window: the citizens are entitled to require that the legislature itself shall cause all public taxation to
be fair and equal in proportion to the value of'property " ( and that is what * cooley * means by
apportionment of taxation ), " so that no class of individuals, and no species of property shall be
unduly assessed. " The treaties I have quoted between Great Britain and China, binding on the
Dominion and on us in British Columbia, secure to the Chinese, just as the treaties between Great
Britain and other foreign countries secure to other foreigners, the same rights in regard to the
equality of taxation which I have described as being enjoyed by citizens of this country. These
treaties have the force of international law, and are continued most strongly against the party for
whose benefit they are introduced. In the case of the Chinese treaties, they were forced at the
point of the bayonet on China, to obtain a right for us to enter China, and in return for a similar
permission to us, full permission was given for the Chinese to trade and reside in British dominions
everywhere.
Pro Score: 0.9364
# Print out the top 5 windows with the highest "Cons" scores
top_cons_windows = all_scores.nlargest(5, 'Cons')
print("\nTop 5 windows with the highest 'Cons' scores:\n")
for _, row in top_cons_windows.iterrows():
wrapped_para = textwrap.fill(row['Text'], width=100)
print(f"Author: {row['Author']}\nWindow: {wrapped_para}\nCons Score: {row['Cons']:.4f}\n")
Top 5 windows with the highest 'Cons' scores:
Author: Begbie
Window: ordinary rule must i think be observed, viz., the subjects of the " other licenses " mentioned in
sub - section 9 must have at least somewhat besides taxability ( from which quality no act or thing
is exempt ) in common with " shops, taverns, saloons or auctioneers. " Again suppose some other
licenses, well known elsewhere, taxes as in England on man-servants, on hair powder, on armourial
bearings-would these be authorized by subsection 9? I think not. Indeed if no restriction whatever
be placed on the word " other" in that section; if the Provincial Legislature can insist upon
imposing licenses upon everything and upon every act of life, and tax each licensee at any moment
they please, there would be a very simple way of excluding every Chinaman from the Province, by
imposing a universal tax, not limited to any nationality, of one or two thousand dollars per annum
for a license to Judgment. wear long hair on the back of the head: or to exclude Russians by a
license to wear a beard, or Jews by a license to eat unleavened bread.
Cons Score: 0.9977
Author: Crease
Window: 32 of that by - law ( published in the b. c. gazette of april 20, 1893 ) directs a strict
examination to be made of any vessel and persons coming from [UNK] an infected locality, [UNK]
before any person, luggage or freight or other thing is allowed to be landed from it. Section 35 of
the Health By-Law of 1893 gives the Medical Health Officer power to stop, detain and examine every
person or persons, freight, cargoes, railway and tramway cars coming from a place “infected with a
malignant Judgment. pestilential or infectious disease,” in order to prevent the introduction of the
same into Victoria. The case was tried before a jury upon the issue whether Hongkong, the last port
the steamer left in China, was or not “an infected locality.” To prove that Hongkong was such, Dr.
Davie was placed in the witness box as an expert.
Cons Score: 0.9901
Author: Crease
Window: by the constitution to the province. now, applying this test to the statute before us, let us see
whether and how far its provisions affect, as is alleged, aliens, or trade, or commerce. the aliens
in this case being chinese, the first enquiry must be, what is the object of the act? On applying to
the preamble, we find that it looks like a bill of indictment as against a race not suited to live
among a civilized nation, and certainly does not prepare one for legislation which would encourage
or tolerate their settlement in the country. Indeed, the first lines of the preamble sound an alarm
at the multitude of people coming in, who are of the repulsive habits described in the last part of
the preamble, and prepares one for measures which should have a tendency to abate that alarm by
deterrent influences and enactments which should have the effect of materially lessening the number
of such undesirable visitors.
Cons Score: 0.9883
Author: Begbie
Window: even that point of view these laundries were taxable, for that the laundry men though they were very
certainly not keeping shops, were very analogus to auctioneers. i rather think that the auctioneers
would repudiate this alleged similarity of their occupation to that of a chinese washerman. i cannot
perceive it. An auctioneer has very extensive authority and important duties; he prepares
advertisements and surveys, disposes property in lots, advises as to prices, and generally is the
agent of both parties to the contract of sale. There is nothing of all BEGBIE. C.J. this in a
laundry; and I feel strongly inclined to think that laundries are not taxable under this sub-
section at all, bearing no analogy to either "shops, saloons, taverns or auctioneers." But without
deciding on this ground there is a still more serious obstacle against supporting this clause 11 of
the Provincial Act of 1885, as being within Section 92, subseetion 9. The taxation by way of license
authorized by that sub-section 9 is to be "in order to the raising a revenue for Provincial, local
or Municipal purposes."
Cons Score: 0.9882
Author: Begbie
Window: tax, not limited to any nationality, of one or two thousand dollars per annum for a license to
judgment. wear long hair on the back of the head : or to exclude russians by a license to wear a
beard, or jews by a license to eat unleavened bread. No Chinaman will shave the back of his head; no
true moujik will shave his chin. There might be a tax on a license to register lands above a certain
value; and we might have a graduated property tax. The opinion, therefore, of the majority of the
Judges in Severn's case, seems more probable. There must I think be some limitation placed on the
licensing power by the word " other." Mr. Yates argued from even that point of view these laundries
were taxable, for that the laundry men though they were very certainly not keeping shops, were very
analogus to auctioneers. I rather think that the auctioneers would repudiate this alleged similarity
of their occupation to that of a Chinese washerman. I cannot perceive it.
Cons Score: 0.9851
# Calculate the mean scores and median scores for each author
mean_scores = all_scores.groupby("Author")[["Pro", "Neutral", "Cons"]].mean()
median_scores = all_scores.groupby("Author")[["Pro", "Neutral", "Cons"]].median()
print("Mean scores by author:")
print(mean_scores)
print("\nMedian scores by author:")
print(median_scores)Mean scores by author:
Pro Neutral Cons
Author
Act 1884 0.161385 0.168683 0.669932
Begbie 0.256219 0.156091 0.587689
Crease 0.231430 0.169689 0.598881
Median scores by author:
Pro Neutral Cons
Author
Act 1884 0.154723 0.227726 0.695607
Begbie 0.135632 0.170300 0.646620
Crease 0.167985 0.162842 0.613651all_scores['Text'] = all_scores['Text'].apply(lambda t: wrap_text(t, width = 50))
fig = px.scatter(
all_scores,
x="Pro",
y="Cons",
color="Author",
hover_data=["Text"],
title="Pros vs Cons Scores by Author",
width=800,
height=600
)
fig.update_traces(marker=dict(size=5))
fig.show()While both approaches identified the Chinese Regulation Act of 1884 as more discriminatory toward Chinese immigrants, and the relative positions of the three author groups matched expectations, the zero-shot results remain sensitive to candidate-label phrasing and textual context.
For instance, the window
…act the legal presumption of innocence until conviction is reversed ; in every case the onus probandi, though in a statute highly penal, is shifted from the informant on to the shoulders of the accused, and he a foreigner not knowing one word of the law, or even the language of the accuser. In other words, every Chinese is guilty until proved innocent—a provision which fills one conversant with subjects with alarm; for if such a law can be tolerated as against Chinese, the precedent is set, and in time of any popular outcry can easily be acted on for putting any other foreigners or even special classes among ourselves, as coloured people, or French, Italians, Americans, or Germans, under equally the same law. That certainly is interfering with aliens. The proposition that it is a Provincial tax for revenue purposes, supposing it to be so intended under the provisions of the Act, is so manifestly calculated to defeat that object, by diminishing the numbers of the members of the persons to be affected by it, that it is difficult to regard it in that light, or in any other light than an indirect mode of getting rid of persons whom it affects out of the country.
is classified as “cons” by the zero-shot classification, which is not accurate, as it essentially reflects Crease’s criticism of the discriminatory nature of the law, and there is no indication that he supports the unequal treatment of Chinese immigrants in this passage.
This highlights the limitations of zero-shot classification for historical legal texts, where semantics, context, and rhetorical devices are often difficult for models to capture accurately.
This example emphasizes the importance of human interpretation in understanding positions in historical texts. It also highlights the need for care when defining candidate labels so they map clearly to the stance categories of interest. Machine learning techniques should therefore be used as auxiliary tools in historical research.
Now that we have examined topic alignment and quantified stance using zero-shot classification, we synthesize the results to evaluate how thematic emphasis correlates with expressed stance. By combining TF-IDF keywords, embedding-based topic anchors, and zero-shot probabilities, we assess whether emphasis on themes such as “labor”, “taxation”, or “legislation” corresponds to pro, neutral, or anti-discriminatory language across authors and documents.
The steps we will take are as follows:
# define a function to clean text for matching
def clean_text(text):
text = text.lower()
text = re.sub(r'[^\w\s]', '', text)
return text.strip()
# Convert the similarity DataFrame to wide format
similarity_wide = similarity_df.pivot(index=['Author','Text'], columns='Topic', values='Similarity Score').reset_index()
# Clean the text for matching
similarity_wide['Clean Text'] = similarity_wide['Text'].apply(clean_text)
print(f"The total size of our corpus is {len(similarity_wide)} sentences.")The total size of our corpus is 125 sentences.# Clean the text in df_scores for matching
df_scores['Clean Text'] = df_scores['Text'].apply(clean_text)
# Match the cleaned text in similarity_wide with df_scores
matched_rows = []
for _, row in similarity_wide.iterrows():
match = df_scores[df_scores['Clean Text'] == row['Clean Text']]
if not match.empty:
matched_row = {
'Author': row['Author'],
'Text': row['Text'],
'Pro': match['Pro'].values[0] if 'Pro' in match else None,
'Neutral': match['Neutral'].values[0] if 'Neutral' in match else None,
'Cons': match['Cons'].values[0] if 'Cons' in match else None,
**row.drop(['Author', 'Text', 'Clean Text']).to_dict()
}
matched_rows.append(matched_row)
# Create a DataFrame from the matched rows
merged_df = pd.DataFrame(matched_rows)
print(f"The size of our merged corpus is {len(merged_df)} sentences.")
merged_df.head()The size of our merged corpus is 125 sentences.| Author | Text | Pro | Neutral | Cons | labor | legislation | license | taxation | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Act 1884 | An Act to regulate the Chinese population of B... | 0.004440 | 0.008335 | 0.987225 | 0.570956 | 0.700714 | 0.635554 | 0.634904 |
| 1 | Act 1884 | And whereas it is expedient to pass special la... | 0.002405 | 0.006154 | 0.991441 | 0.579225 | 0.539790 | 0.592184 | 0.463144 |
| 2 | Act 1884 | Any Chinese who shall be found mining for gold... | 0.007647 | 0.003881 | 0.988472 | 0.623228 | 0.564811 | 0.626684 | 0.493289 |
| 3 | Act 1884 | Any Chinese who shall be found within the Prov... | 0.002490 | 0.002559 | 0.994950 | 0.613431 | 0.553215 | 0.630230 | 0.478543 |
| 4 | Act 1884 | Any Chinese who shall lend his licence or free... | 0.004562 | 0.008456 | 0.986982 | 0.598947 | 0.524048 | 0.597659 | 0.457110 |
# Ensure wrapped text for hover
merged_df['wrapped_text'] = merged_df['Text'].apply(lambda t: wrap_text(t, width=50))
author_order = ['Crease', 'Begbie', 'Act 1884']
color_map = {'Crease': '#1f77b4', 'Begbie': '#d62728', 'Act 1884': '#2ca02c'}
def plot_topic_vs_stance(df, topic='labor', authors=None, color_map=None, show_regression=True,
width=800, height=800):
pio.renderers.default = "plotly_mimetype+notebook_connected"
df = df.copy()
# Prepare text wrapping if needed
if 'wrapped_text' not in df.columns:
df['wrapped_text'] = df['Text'].apply(lambda t: wrap_text(t, width=50))
# Default authors if not provided
if authors is None:
authors = df['Author'].unique()
# Function to create a slightly darker variant of a color for regression lines
def darken_color(color, factor=0.7):
if isinstance(color, str) and color.startswith('#'):
hex_color = color.lstrip('#')
rgb = tuple(int(hex_color[i:i+2], 16) for i in (0, 2, 4))
darkened_rgb = tuple(int(c * factor) for c in rgb)
return f"rgb({darkened_rgb[0]}, {darkened_rgb[1]}, {darkened_rgb[2]})"
return color # Return as-is if not hex format
default_colors = [
'#2E86C1', '#E74C3C', '#28B463', '#F39C12', '#8E44AD',
'#17A2B8', '#FD7E14', '#20C997', "#87020F", '#6F42C1'
]
if color_map is None:
color_map = {author: default_colors[i % len(default_colors)]
for i, author in enumerate(authors)}
# More distinct symbols
symbols = ['circle', 'square', 'diamond', 'triangle-up', 'star', 'hexagon']
author_symbols = {author: symbols[i % len(symbols)] for i, author in enumerate(authors)}
# Create subplots with reduced vertical spacing for a tighter layout
fig = make_subplots(
rows=2, cols=1,
shared_xaxes=True,
subplot_titles=(f"Pro Score vs {topic.title()} Similarity",
f"Cons Score vs {topic.title()} Similarity"),
horizontal_spacing=0.06,
vertical_spacing=0.06
)
# Track which authors have data for legend management
authors_with_data = set()
for author in authors:
df_author = df[df['Author'] == author]
author_color = color_map.get(author, '#7F8C8D')
author_symbol = author_symbols.get(author, 'circle')
# Pro scores (top subplot)
df_pro = df_author.dropna(subset=['Pro', topic])
if len(df_pro) > 0:
authors_with_data.add(author)
fig.add_trace(
go.Scatter(
x=df_pro[topic],
y=df_pro['Pro'],
mode='markers',
marker=dict(
color=author_color,
size=8,
opacity=0.85,
symbol=author_symbol,
line=dict(color='white', width=1.25)
),
name=author,
legendgroup=author,
hovertext=df_pro['wrapped_text'],
hovertemplate=(
f"<b>{author}</b><br>"
f"{topic.title()} Similarity: %{{x:.3f}}<br>"
"Pro Score: %{y:.3f}<br>"
"%{hovertext}<br>"
"<extra></extra>"
),
),
row=1, col=1
)
# Regression
if show_regression and len(df_pro) >= 3:
x_vals = df_pro[topic].values
y_vals = df_pro['Pro'].values
coeffs = np.polyfit(x_vals, y_vals, 1)
x_range = np.linspace(x_vals.min(), x_vals.max(), 100)
y_pred = np.polyval(coeffs, x_range)
fig.add_trace(
go.Scatter(
x=x_range,
y=y_pred,
mode='lines',
line=dict(
color=darken_color(author_color),
width=2,
dash='dot'
),
name=f"{author} trend",
legendgroup=author,
showlegend=False,
hoverinfo='skip'
),
row=1, col=1
)
# Cons scores (bottom subplot)
df_cons = df_author.dropna(subset=['Cons', topic])
if len(df_cons) > 0:
fig.add_trace(
go.Scatter(
x=df_cons[topic],
y=df_cons['Cons'],
mode='markers',
marker=dict(
color=author_color,
size=8,
opacity=0.85,
symbol=author_symbol,
line=dict(color='white', width=1.25)
),
name=author,
legendgroup=author,
showlegend=False,
hovertext=df_cons['wrapped_text'],
hovertemplate=(
f"<b>{author}</b><br>"
f"{topic.title()} Similarity: %{{x:.3f}}<br>"
"Cons Score: %{y:.3f}<br>"
"%{hovertext}<br>"
"<extra></extra>"
),
),
row=2, col=1
)
if show_regression and len(df_cons) >= 3:
x_vals = df_cons[topic].values
y_vals = df_cons['Cons'].values
coeffs = np.polyfit(x_vals, y_vals, 1)
x_range = np.linspace(x_vals.min(), x_vals.max(), 100)
y_pred = np.polyval(coeffs, x_range)
fig.add_trace(
go.Scatter(
x=x_range,
y=y_pred,
mode='lines',
line=dict(
color=darken_color(author_color),
width=2,
dash='dot'
),
showlegend=False,
hoverinfo='skip'
),
row=2, col=1
)
# Update axes styling
fig.update_xaxes(
title_text="",
showgrid=True,
gridwidth=1,
gridcolor='rgba(128,128,128,0.18)',
zeroline=True,
zerolinewidth=1,
zerolinecolor='rgba(128,128,128,0.25)',
row=1, col=1
)
fig.update_xaxes(
title_text=f"{topic.title()} Topic Similarity",
showgrid=True,
gridwidth=1,
gridcolor='rgba(128,128,128,0.18)',
zeroline=True,
zerolinewidth=1,
zerolinecolor='rgba(128,128,128,0.25)',
row=2, col=1
)
fig.update_yaxes(
title_text="Pro Score",
showgrid=True,
gridwidth=1,
gridcolor='rgba(128,128,128,0.18)',
zeroline=True,
zerolinewidth=1,
zerolinecolor='rgba(128,128,128,0.25)',
row=1, col=1
)
fig.update_yaxes(
title_text="Cons Score",
showgrid=True,
gridwidth=1,
gridcolor='rgba(128,128,128,0.18)',
zeroline=True,
zerolinewidth=1,
zerolinecolor='rgba(128,128,128,0.25)',
row=2, col=1
)
# Layout: title moved to top left, legend moved to top right
fig.update_layout(
width=width,
height=height,
title=dict(
text=f"Stance Towards Chinese Immigrants vs {topic.title()} Topic Similarity",
x=0.02, # Move title to top left
xanchor='left',
font=dict(size=16, color='#2C3E50'),
pad=dict(t=12, b=20)
),
legend=dict(
title=None,
orientation='v', # Vertical orientation for top right
y=0.98, # Position at top
yanchor='top',
x=0.98, # Position at right
xanchor='right',
bgcolor='rgba(255,255,255,0.92)',
bordercolor='rgba(52,73,94,0.12)',
borderwidth=1,
font=dict(size=11),
traceorder='normal'
),
template="plotly_white",
plot_bgcolor='rgba(248,249,250,0.95)',
margin=dict(t=90, b=80, l=60, r=60),
font=dict(family="Arial, sans-serif", color='#2C3E50')
)
# Subplot title styling (keep compact)
if len(fig.layout.annotations) >= 2:
fig.layout.annotations[0].update(font=dict(size=13, color='#34495E'))
fig.layout.annotations[1].update(font=dict(size=13, color='#34495E'))
fig.show()
return# Example usage for all four topics:
plot_topic_vs_stance(merged_df, topic="labor", color_map=color_map, show_regression=True)# Create visualization for legislation
plot_topic_vs_stance(merged_df, topic="legislation", color_map=color_map, show_regression=True)# Create visualization for license
plot_topic_vs_stance(merged_df, topic="license", color_map=color_map, show_regression=True)# Create visualization for taxation
plot_topic_vs_stance(merged_df, topic="taxation", color_map=color_map, show_regression=True)Correlation coefficients quantify the strength and direction of the relationship between topic alignment and each stance score. A positive correlation indicates that as topic alignment increases, the stance score also tends to increase (for example, more pro-discriminatory language). A negative correlation indicates the opposite trend (for example, more anti-discriminatory language). The closer the coefficient is to 1 or -1, the stronger the relationship.
The math behind correlation coefficients is as follows: \[ \text{corr}(X, Y) = \frac{\text{cov}(X, Y)}{\sigma_X \cdot \sigma_Y} \] Where \(X\) and \(Y\) are the topic alignment scores and stance scores, respectively, \(\text{cov}(X, Y)\) is the covariance between the two variables, and \(\sigma_X\) and \(\sigma_Y\) are their standard deviations.
# Summarize the correlation between topic similarity and stance scores
correlation_results = []
# Overall correlations (across all authors)
for topic in ['labor', 'legislation', 'license', 'taxation']:
for stance in ['Pro', 'Cons']:
corr = merged_df[[topic, stance]].corr().iloc[0, 1]
correlation_results.append({
'Author': 'All Authors',
'Topic': topic,
'Stance': stance,
'Correlation': corr
})
# Correlations by individual author
for author in merged_df['Author'].unique():
author_data = merged_df[merged_df['Author'] == author]
for topic in ['labor', 'legislation', 'license', 'taxation']:
for stance in ['Pro', 'Cons']:
corr = author_data[[topic, stance]].corr().iloc[0, 1]
correlation_results.append({
'Author': author,
'Topic': topic,
'Stance': stance,
'Correlation': corr
})
correlation_df = pd.DataFrame(correlation_results)
# Pivot the DataFrame to show correlations in a more readable format
correlation_pivot = correlation_df.pivot_table(
index=['Author', 'Topic'],
columns='Stance',
values='Correlation'
).reset_index()
correlation_pivot.columns.name = None # Remove the name of the columns index
# Convert to wide format for better display
correlation_wide = correlation_pivot.pivot_table(
index='Author',
columns='Topic',
values=['Pro', 'Cons']
).round(4)
print("\nCorrelation Coefficients of Topic Alignments and Pro/Cons Scores by Each Author:")
correlation_wide
Correlation Coefficients of Topic Alignments and Pro/Cons Scores by Each Author:| Cons | Pro | |||||||
|---|---|---|---|---|---|---|---|---|
| Topic | labor | legislation | license | taxation | labor | legislation | license | taxation |
| Author | ||||||||
| Act 1884 | 0.0934 | 0.2507 | 0.1823 | 0.2228 | -0.1448 | -0.2939 | -0.2435 | -0.2683 |
| All Authors | -0.0623 | -0.0503 | -0.0611 | -0.0813 | 0.0549 | 0.0032 | 0.0404 | 0.0246 |
| Begbie | 0.0595 | 0.0874 | 0.0502 | 0.1064 | -0.0610 | -0.0947 | -0.0551 | -0.1219 |
| Crease | 0.1060 | 0.0407 | 0.0981 | -0.0061 | -0.0702 | -0.0835 | -0.0834 | -0.0480 |
These enable us to see how different topics relate to the stances expressed in the texts, and whether certain topics are more associated with pro‑, neutral, or anti‑discriminatory language.
In this workshop, we explored how to effectively digitize historical text documents and apply computational methods to analyze legal texts on Chinese immigration in British Columbia. We used TF-IDF analysis, word embeddings, stance embeddings, zero-shot classification, and topic modeling to examine language patterns and compare author positions.
The results of our analysis matched the expectations based on previous historical research, confirming that Crease and Begbie indeed held similar positions on the issue, while the Chinese Regulation Act reflected a more discriminatory stance (with higher “Cons” scores overall). In addition, we found interesting clustering patterns in the UMAP projection of the stance embeddings, which poses further questions for investigation, such as what each UMAP cluster represents and what each axis in the UMAP projection means. We also identified several key topics that were prominent in the texts, and explored how these topics relate to the stances expressed in the texts using zero-shot classification scores and topic alignment scores.
These techniques also have clear limitations: pre-trained models may contain biases and may not capture the full nuance of historical legal language. Topic-alignment and zero-shot outputs are sensitive to label wording and context, so results should be interpreted cautiously. Machine learning should therefore be treated as an auxiliary research tool, with human interpretation remaining essential.
In conclusion, this workshop offers a quantitative perspective on analyzing historical legal materials while emphasizing the limits of these methods and the continuing importance of human interpretation. We hope it provides a useful foundation for combining computational techniques with traditional humanities and social-science research.