Text Analysis Overview
Section 1: Traditional Qualitative Coding
Qualitative research often begins with hand-coded analysis, where researchers create a codebook and apply categories to text manually
The convention
Imagine you have a giant pile of stories, surveys or interviews, researchers first make a list of buckets (this list is called a codebook). Then one by one, they read the text and put each piece into the right bucket.
Examples of buckets might be emotions such as happy, angry, sad; or topics about money, about family, etc. Researchers can freely decide the buckets they need.
1.1 Inductive Coding
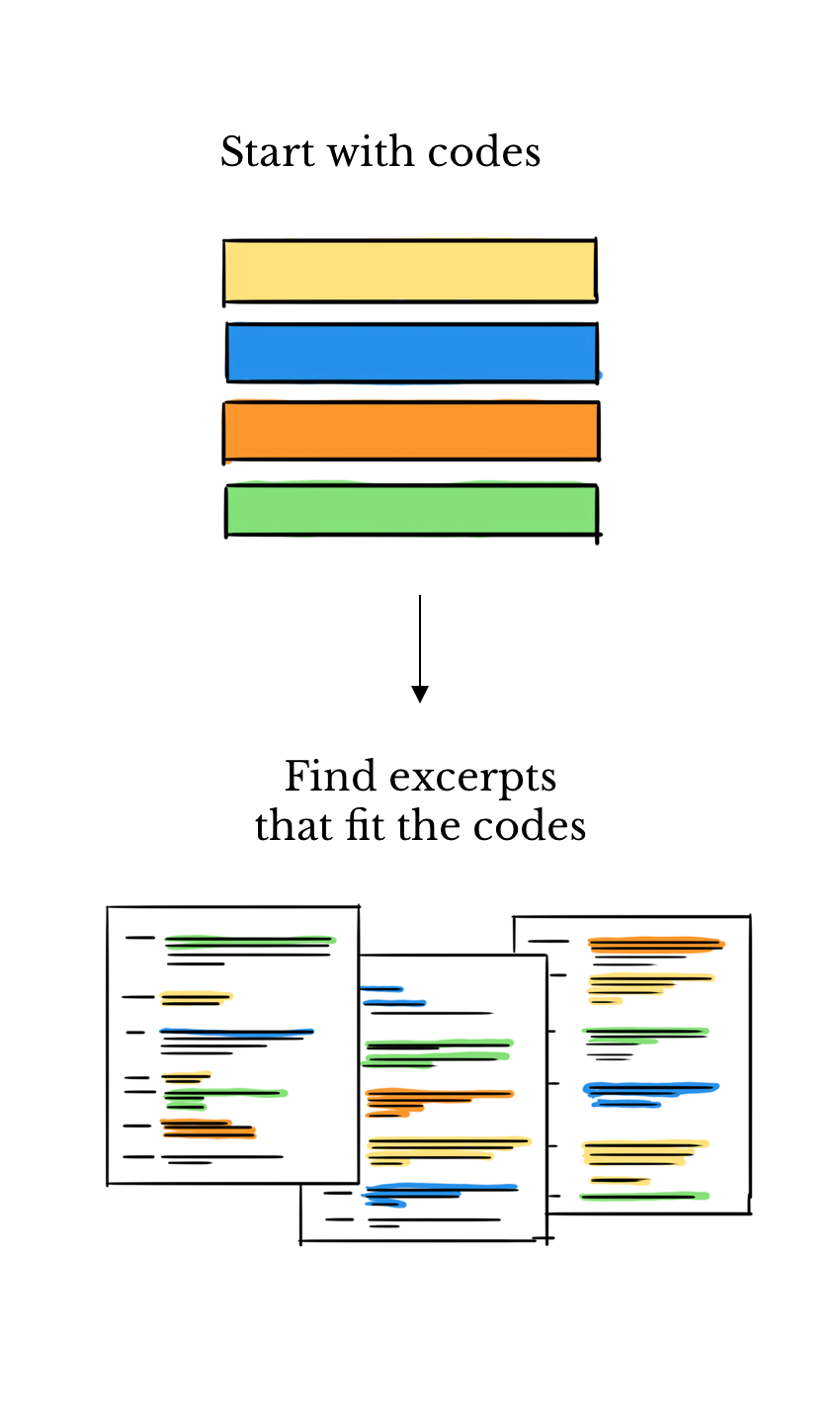
This is called hand-coding because people do it by hand and not a computer. It works well but it’s slow and requires people who have been expertly trained. It also works the other way around, you can read the text and come up with buckets.
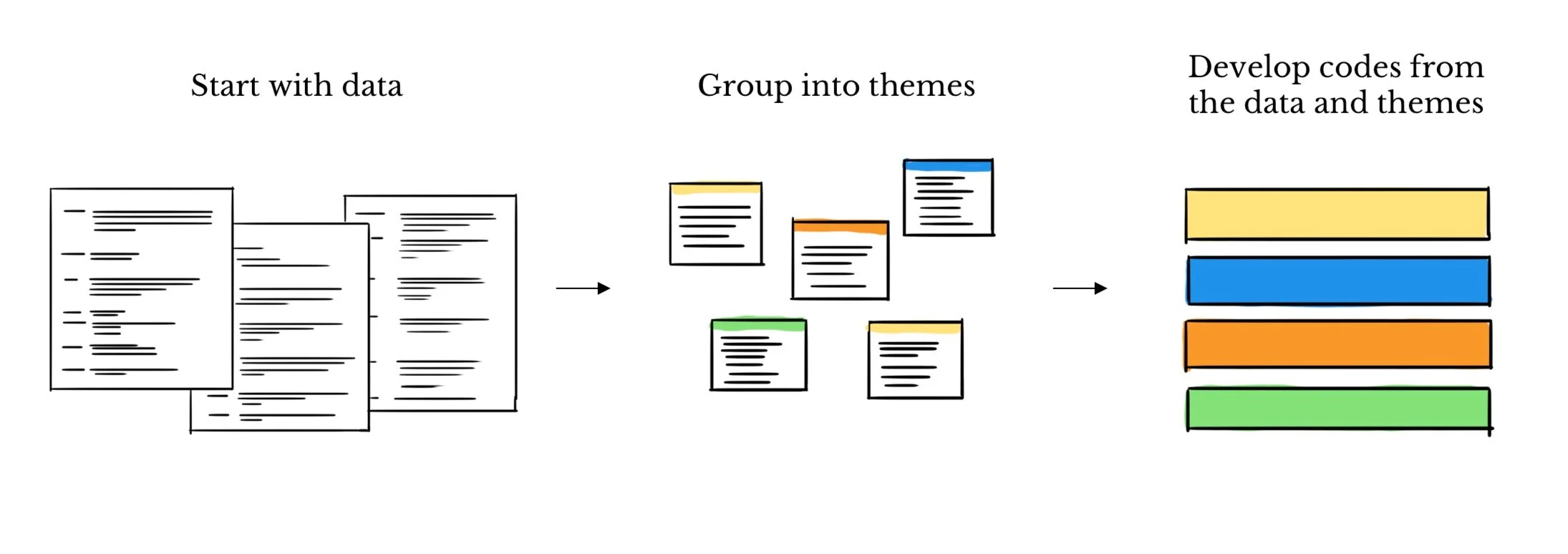
Example of Inductive Coding
Imagine coding voter interviews into pre-set buckets like Economy, Healthcare, Immigration.
| Comment | Code (Bucket) | Why? |
|---|---|---|
| “Groceries and gas are too expensive.” | Economy | Clearly about financial concerns. |
| “I want better access to doctors.” | Healthcare | Fits the “Healthcare” bucket. |
| “The government should secure the border.” | Immigration | Matches the “Immigration” bucket. |
| “I don’t trust politicians at all.” | (none) | Doesn’t fit the pre-set buckets, so it’s skipped. |
- Coding helps researchers move from raw words to structured insights.
- It turns scattered comments into clear evidence about what people care about.
1.2 Recent Updates: Crowdsourcing
A Newer Way
Hand-coding takes a long time. So now, people sometimes ask lots of regular internet workers to help, this approach is called crowdsourcing.
Examples
Amazon Mechanical Turk (MTurk)
MTurk is an online marketplace for small tasks. Researchers or companies post simple jobs (like labeling sentences, clicking through images, or filling surveys). Workers around the world complete these tasks for small payments. In research, MTurk is often used to quickly get lots of human-coded data without hiring a big team of experts.
Example usage: A researcher who uploads 1,000 tweets and asks MTurk workers to tag them as positive, negative, or neutral.
-
Prolific is also an online platform for research participants, but it’s designed specifically for academic studies. Participants sign up to take part in surveys, experiments, and labeling tasks. Researchers like it because Prolific tends to have higher-quality, more reliable participants compared to MTurk. It also gives access to specific demographics (age, country, education, etc.), which is useful for social science studies.
Example usage: A political science researcher who runs a survey about voting behavior, targeting only UK residents, using Prolific.
Inter-Coder Reliability
Instead of only using experts, researchers pay many workers online to sort the text.
- Good part: This is way faster and cost-efficient.
- Bad part: Workers don’t always agree. For instance you and I may disagree whether pineapple belongs on pizza.
When two researchers code the same text, they don’t always agree.
- One coder might tag “My boss always calls me by a nickname instead of my real name” as Workplace Inequality.
- Another coder might put it under Identity & Respect.
Why it matters: Inter-coder reliability helps show that your coding system is trustworthy and not just one person’s opinion.
How do researchers measure agreement?
Percent Agreement
Just count how often coders pick the same label. This is easy, but doesn’t account for chance.Cohen’s Kappa (κ)
Adjusts for agreement that could happen just by chance. Values range from -1 (no agreement) to 1 (perfect agreement).Krippendorff’s Alpha
More flexible. Works with multiple coders, different types of data, and missing values.
Often used in social science research.
1.3 Section Conclusion
In this section, we explored the foundational methods of qualitative text analysis, including traditional hand-coding and crowdsourcing approaches. These techniques, while effective, can be time-intensive and rely heavily on human expertise.
As we move forward, we’ll delve into how modern computational methods, powered by machine learning, are revolutionizing text analysis—making it faster, scalable, and more efficient. Let’s see how technology is transforming this process.
Section 2: Computational Text Analysis
Machine Learning (ML) is a transformative field that combines statistics, computer science, and artificial intelligence to enable computers to learn from data and make predictions or decisions without being explicitly programmed.
What is ML?
ML focuses on building algorithms that can identify patterns in data, adapt to new information, and improve performance over time.Why it matters for data analysis:
ML automates tasks like classification, clustering, and regression, making it faster and more scalable to extract insights from large and complex datasets.
ML is the backbone of modern data analysis, enabling researchers and organizations to unlock the full potential of structured and unstructured data.
We can split up ML-based methods into two categories: Supervised and Unsupervised learning.
2.1 Supervised Machine Learning
In supervised learning, a model is trained on a dataset of documents that are already assigned human-provided annotations (labels).
Supervised learning typically takes 3 steps:
- Training: The model first analyzes this pre-labeled data to learn the features (ex: linguistic patterns, structures, semantic relationships) associated with each category.
- Testing: With a held-out, unseen annotated test data, we evaluate how well the model performs by comparing the actual labels and the labels classified by the model.
- Application: Once trained and evaluated, the model can then process new, unseen text for tasks like entity identification, sentiment analysis, translation, and other classification tasks.
2.1.1 But first, text preprocessing…
Before we can proceed with an analysis of our texts, we need to preprocess them using a series of steps.
We do this because supervised learning models cannot work with raw text1: Models like Logistic Regression, Support Vector Machines, and Naive Bayes are fundamentally mathematical algorithms that operate on numerical data. They have no inherent ability to understand strings of text.
Text preprocessing usually involves the following steps:
- Tokenization
- Text normalization (sometimes)
- Stop word removal
- Vectorization (BoW, TF-IDF, Embeddings)
Tokenization and stopword removal
A token is a fundamental unit of text, often times a word, or a subword of a word, created by segmenting a larger string of text for a model to process.
Sentence: The pack of chihuahuas chased after the frightened cat.
List of tokens: ['the', 'pack', 'of', 'chihuahua', '##s', 'chased', 'after', 'the', 'frightened', 'cat', '.']
String of tokens: the pack of chihuahua ##s chased after the frightened cat .An example using bert-based-uncased’s autotokenizer.
A stopword is an extremely common word in natural language, such as “the,” “a,” or “is”, that is often removed from text during preprocessing as it carries virtually no meaningful information on its own.
Since these words add noise without contributing any unique information, removing them allows the model to focus on the more meaningful words that actually differentiate documents.
Original Tokens: ['the', 'pack', 'of', 'chihuahua', '##s', 'chased', 'after', 'the', 'frightened', 'cat', '.']
Tokens (stopwords removed): ['pack', 'chihuahua', '##s', 'chased', 'frightened', 'cat', '.']Text normalization
Sometimes, a researcher may want to add a few additional preprocessing steps. These can include:
- Stemming: Reducing words to their root form, or stem.
- Lemmatization: Reducing a word to its base or dictionary form, known as the lemma
Text normalization can often be useful, but it isn’t strictly necessary.
In fact, stemming and lemmatization of tokens can reduce topic readability as well as conflate terms with different meanings2.
That’s not to say don’t stem/lemmatize, just don’t do so blindly– think very carefully about why you are doing so and how it affects your model.
Vectorization: Bag of Words
ML models are fundamentally based on math, so they require structured numerical data. Vectorization is the process of translating unstructured text into a numerical format.
Different vectorization techniques result in different interpretations of the resulting vectors of numbers. The two simplest vectorization methods are Bag of Words (BoW) and TF-IDF.
What is Bag of Words?
Consider a spreadsheet where each column corresponds to a document, and each row is the the number of times each word (in the document) shows up in the document.
Example:
Sentence: “The pack of chihuahuas chased after the frightened cat.”
Its BoW representation: \(<2,1,1,1,1,1,1,1>\)
Strength:
- Resulting matrix values are extremely easy to interpret.
Limitations:
- Resulting matrix becomes very sparse very fast.
- Context-agnostic: “The dog chased after the cat” has the same matrix representation as “the cat chased after the dog”.
- Every word is treated equally, so common words dominate.
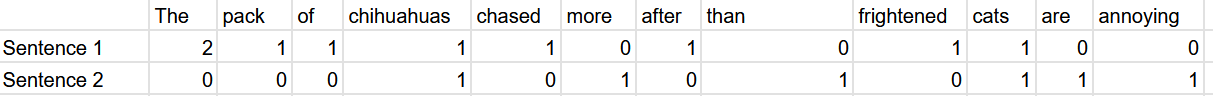
Recall the BoW representation of the two sentences from the previous slide. Now imagine if instead of each document being a single sentence, it was hundreds– even after stopword removal, very frequent words would still dominate and be considered important. Are they actually important? Probably not.

Vectorization: TF-IDF
What if instead of looking at aggregate counts for words, we looked at their importance relative to other documents?
TF-IDF calculates a word’s importance by multiplying its frequency within a document by a score that increases for words that are rare across the entire collection of documents, and penalises for words that are common across documents.
TF-IDF works best with corpora containing many medium-length texts (ex: collections of news articles). In general, the more documents we have, the better this method will perform.
Some useful libraries:
R Language :
- SnowballC
- tidytext
Python Language:
- Scikit-learn
- nltk
2.1.2 Supervised learning statistical frameworks
Supervised methods usually fall into two categories: regression and classification.
Regression is used to predict numeric or continuous value (ex: predicting which year a given court case is from based on its language)
Classification is used to predict class labels or group membership (ex: predicting if the author of a tweet is a Republican or Democrat)
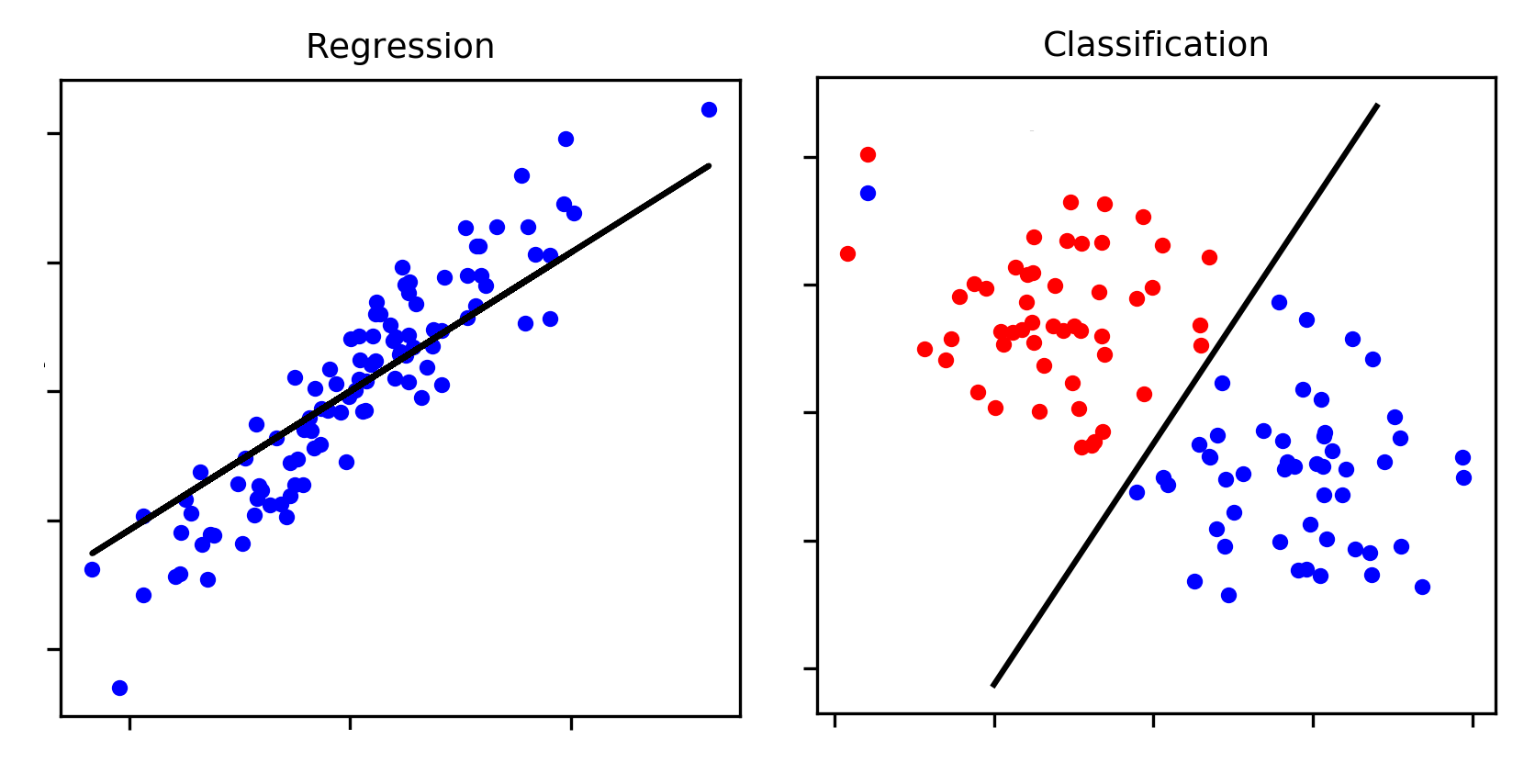
Below, we will provide an overview of a few foundational methods commonly used in supervised learning for text analysis.
Example 1: Naive Bayes Classifier
What is Naive Bayes?
- A Naive Bayes classifier predicts class labels for text based on probabilities.
- Assumes that the presence of a word in a document is independent of the presence of other words.
- Uses pre-labeled data to calculate word probabilities for each class, then applies these probabilities to classify new, unseen texts.
How it works:
- Training Phase: The model calculates the probability of each word appearing in each class (e.g., Jane Austen vs. Herman Melville).
- Prediction Phase: For a new text, the model calculates the probability of it belonging to each class based on the words it contains.It then assigns the text to the class with the highest probability.
Example:
- Task: Classify whether a sentence is from Jane Austen or Herman Melville.
- Sentence: “The white whale swam in the sea.”
- Key Features: Counts of words like “white,” “whale,” “swam,” and “sea.”
Why Melville?
- Words like “whale” and “sea” are far more common in Melville’s writing.
- The model calculates higher probabilities for these words in the Melville class.
- Result: The sentence is classified as Melville.
Strengths:
- It is simple and computationally efficient.
- It works well with small datasets.
Limitations:
- It assumes word independence, which may not always hold true.
- It struggles with complex relationships between words.
Example 2: Logistic Regression
What is Logistic Regression?
- Logistic regression is a statistical method for binary classification tasks (e.g., determining if a sentence belongs to Melville or Austen’s works).
- It calculates the probability of an outcome falling into one of two categories using a sigmoid function.
Key Features:
- No Independence Assumption: Unlike Naive Bayes, logistic regression does not assume features are independent. Instead, it learns how features interact to influence classification.
- Discriminative Model: Focuses on directly learning the boundary that separates classes, rather than modeling the characteristics of each class individually (as in generative models like Naive Bayes).
When to Use:
- Model Interpretability: Coefficients directly indicate the influence of each feature on the outcome.
- Example: A high coefficient on the word “whale” suggests its presence significantly increases the probability of a sentence being classified as Melville’s work.
- Probabilistic Outputs: Provides probabilities for class membership, useful for nuanced decision-making.
Strengths:
- Works well when interpretability and understanding feature contributions are important.
- Suitable for datasets where features interact in complex ways.
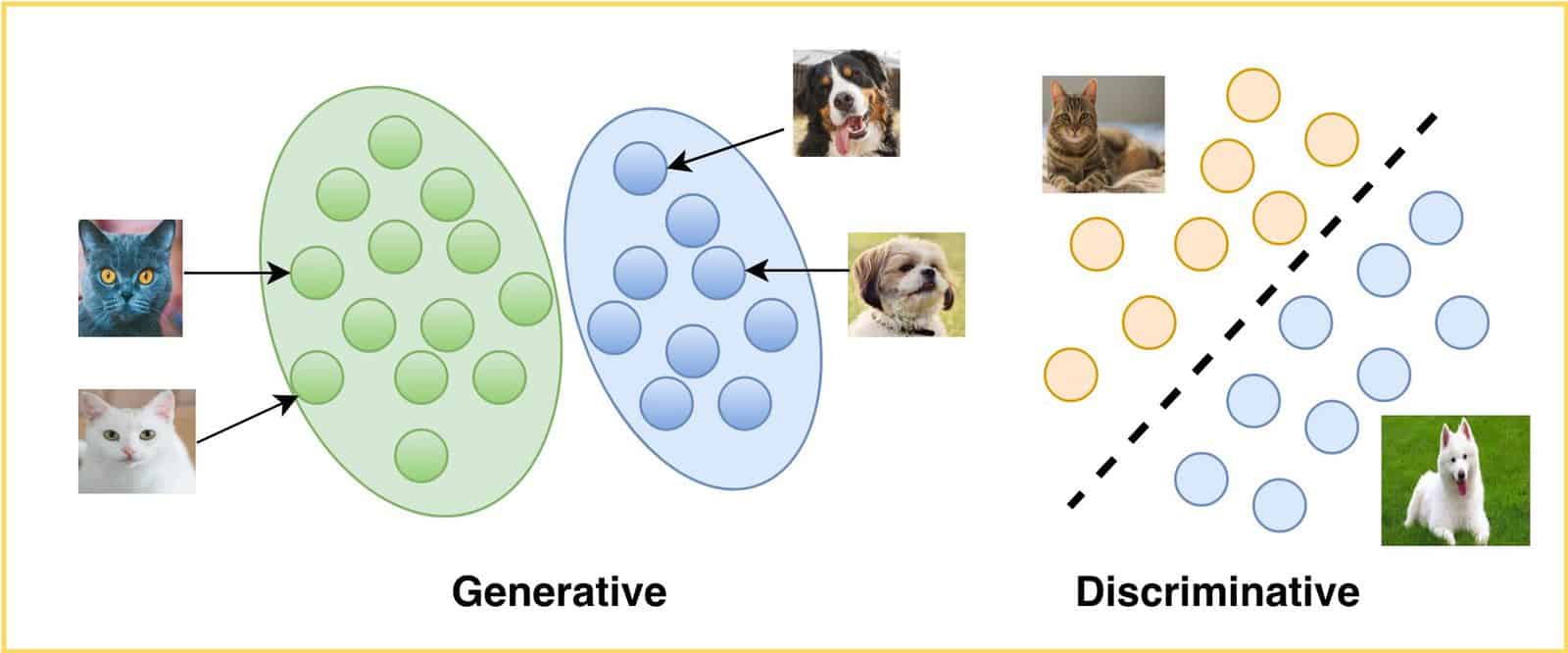
Example 3: Support Vector Machines
What is SVM?
- Support Vector Machines aim to find the best decision boundary between classes.
- The “best” boundary is the one that maximizes the margin (distance) between the classes.
Key Features:
- It focuses on most difficult-to-classify points (support vectors).
- It works well with high-dimensional data (e.g., small datasets with many unique words).
When to Use:
- High-Dimensional Data: Small datasets with many features (e.g., unique words in text).
- Clear Margin of Separation: When classes are well-separated.
- Classification Focus: When probabilities are not required, only class labels.
Strengths:
- It is effective in high-dimensional spaces.
- It is memory efficient: Only support vectors are stored.
- It works well with both linear and non-linear decision boundaries.
Limitations:
- It is sensitive to noise and outliers.
- It requires careful tuning of hyperparameters (e.g., kernel type, regularization).
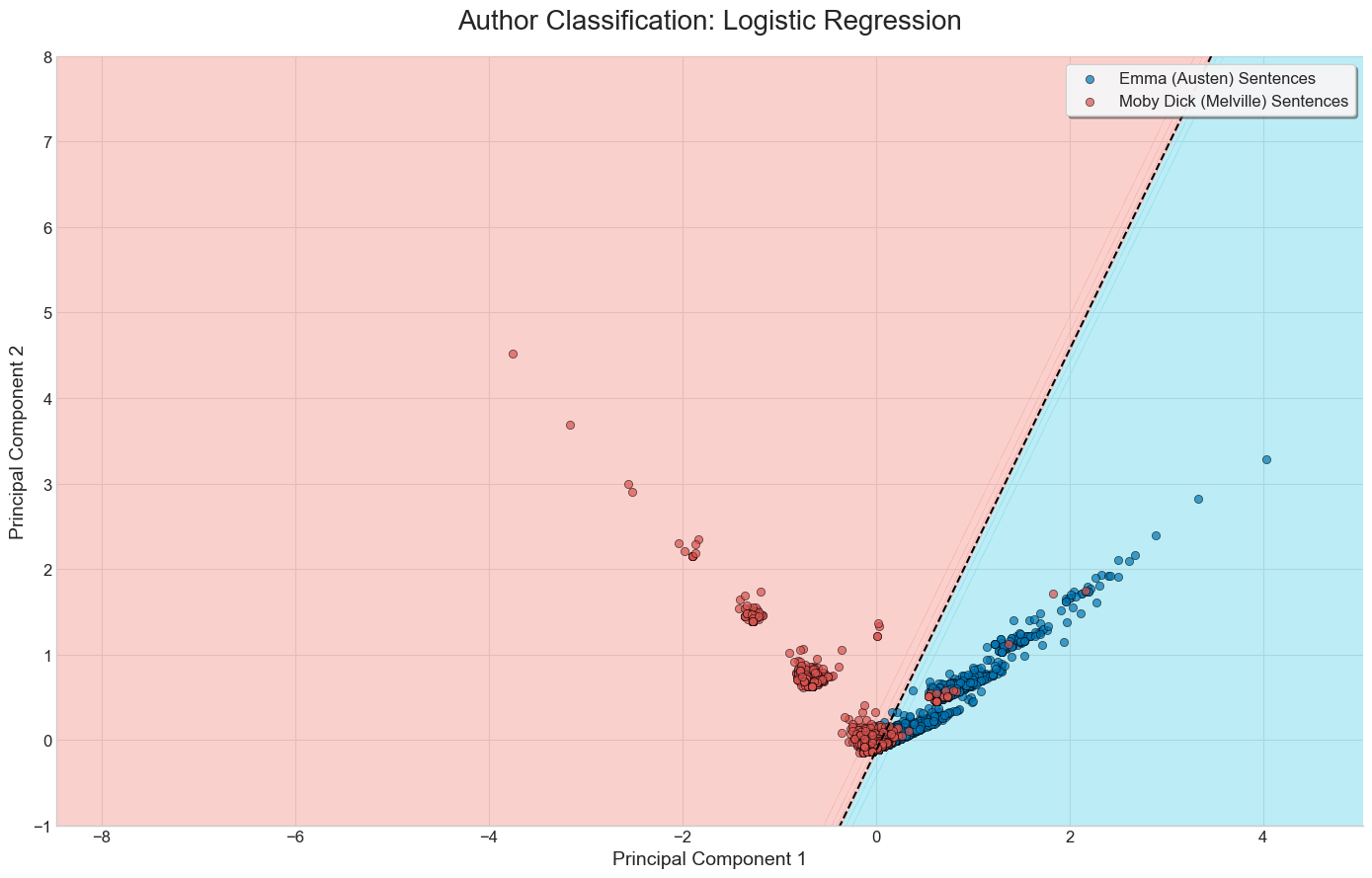
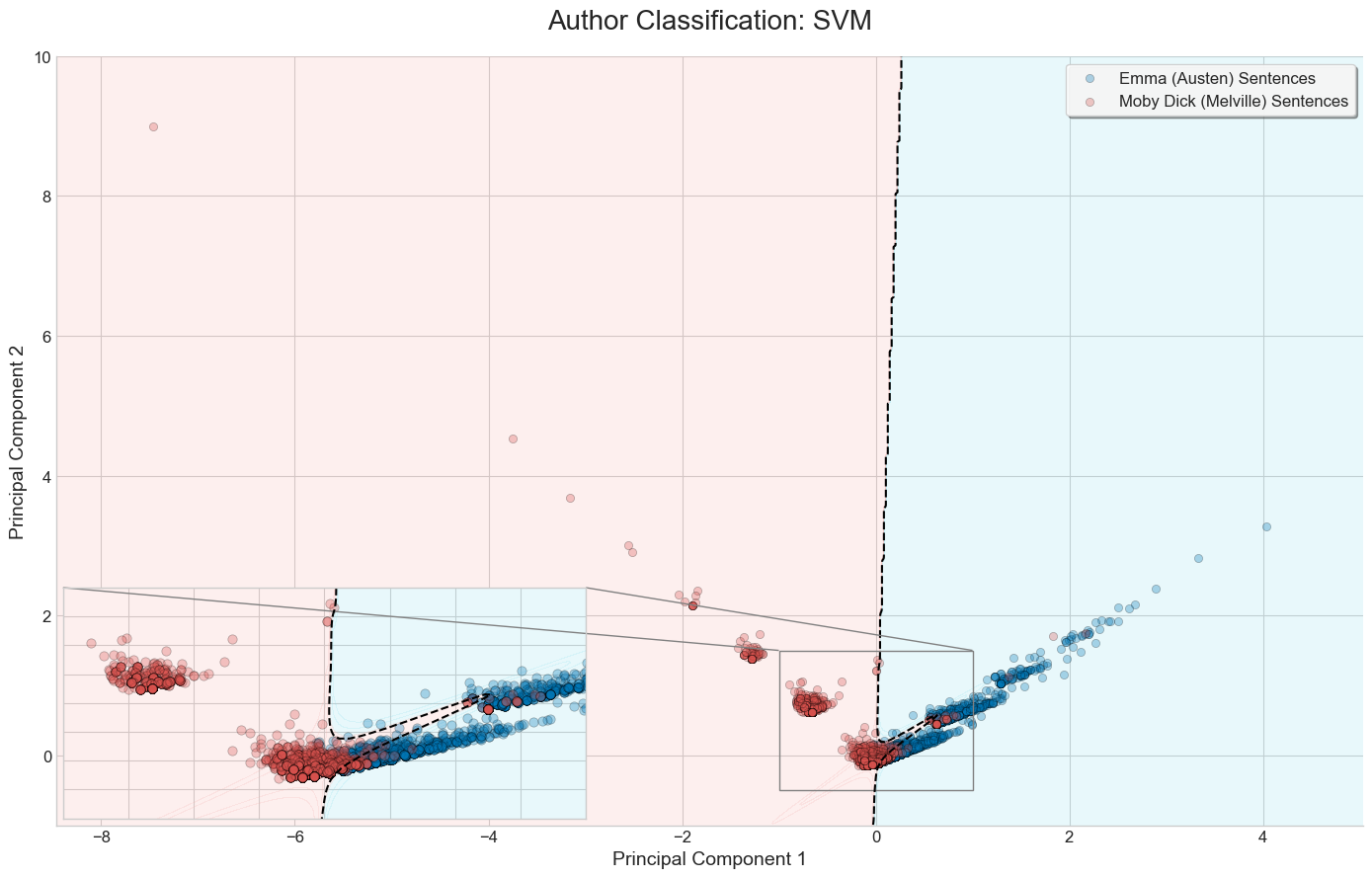
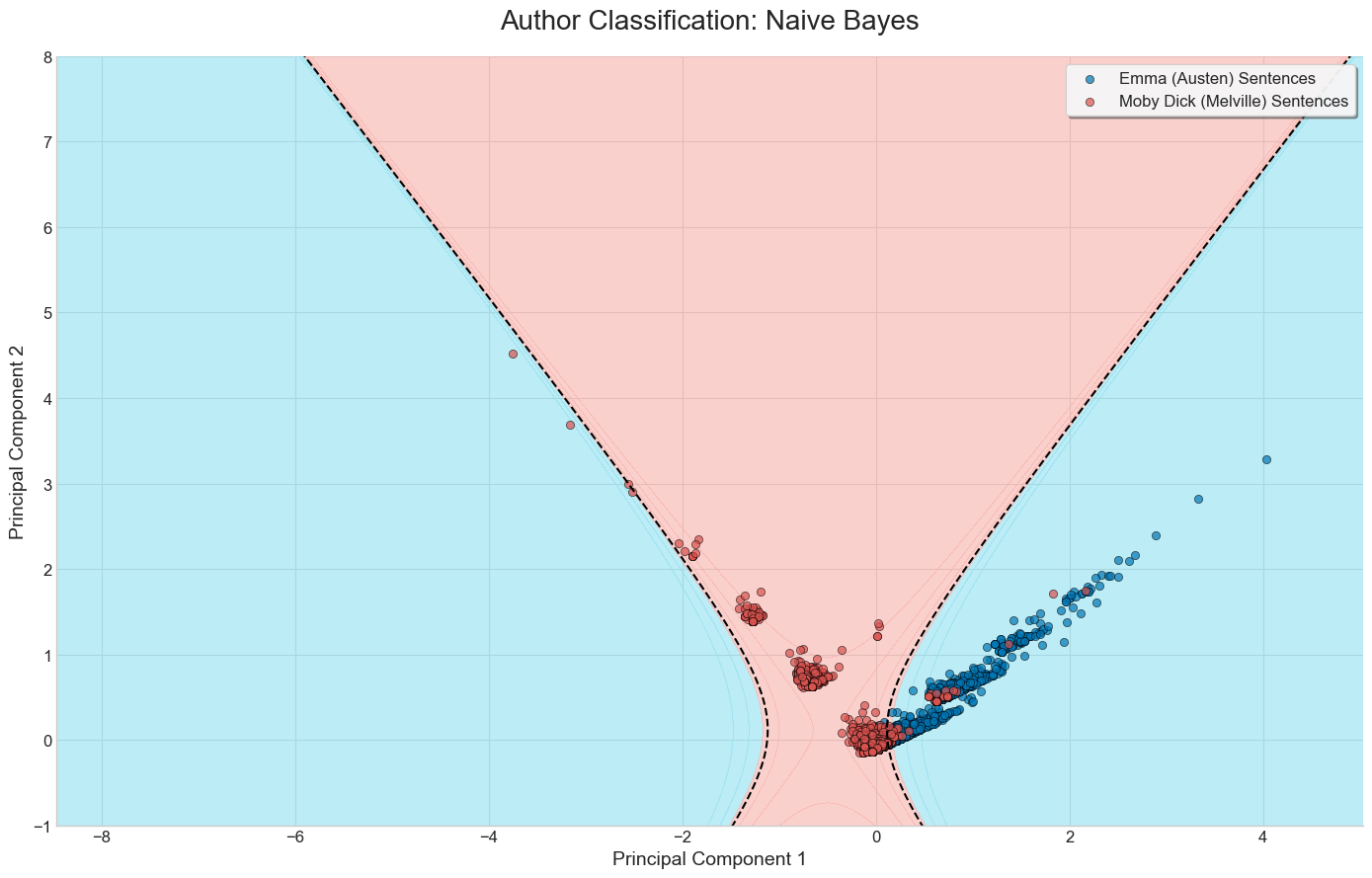
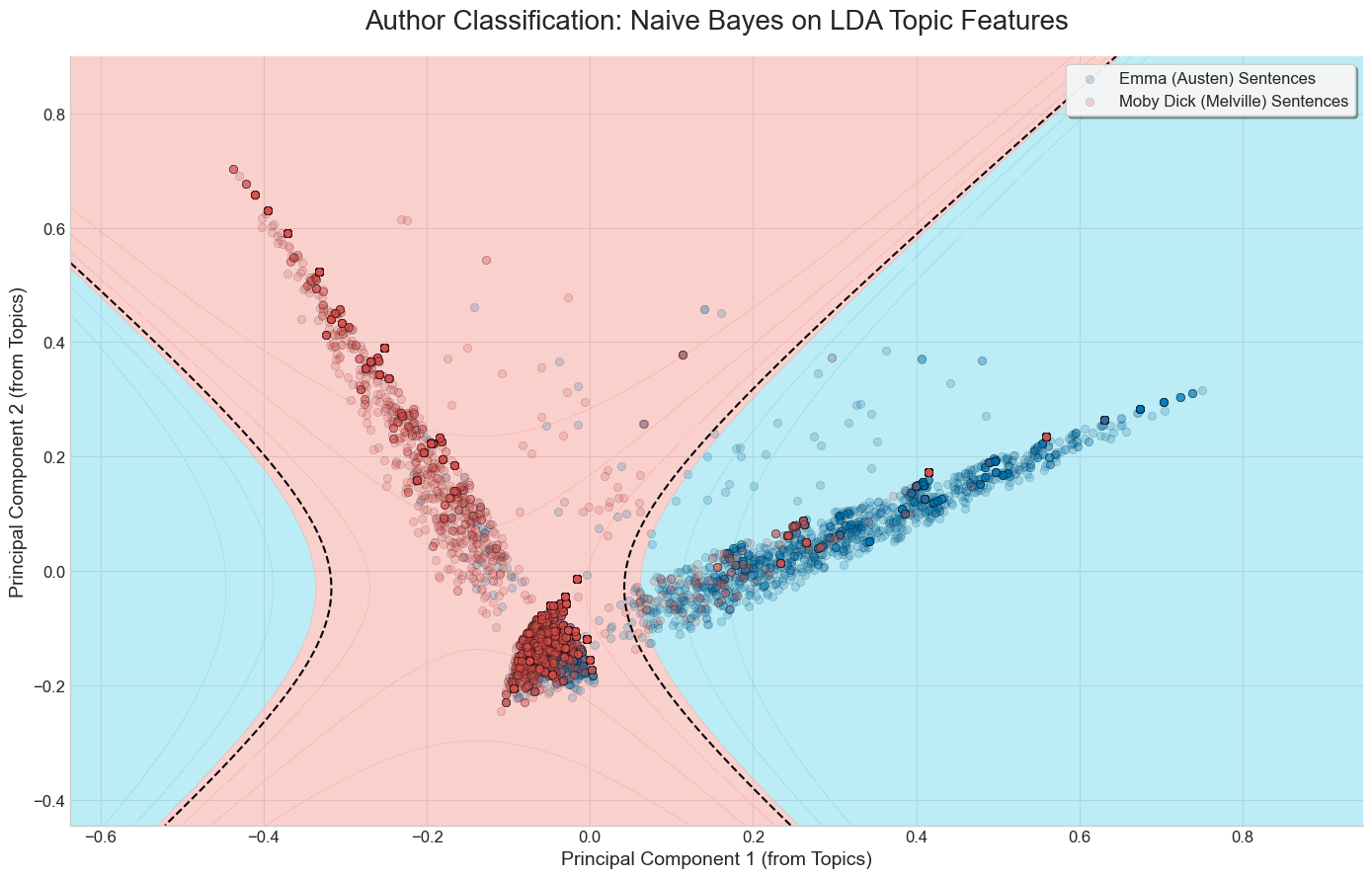
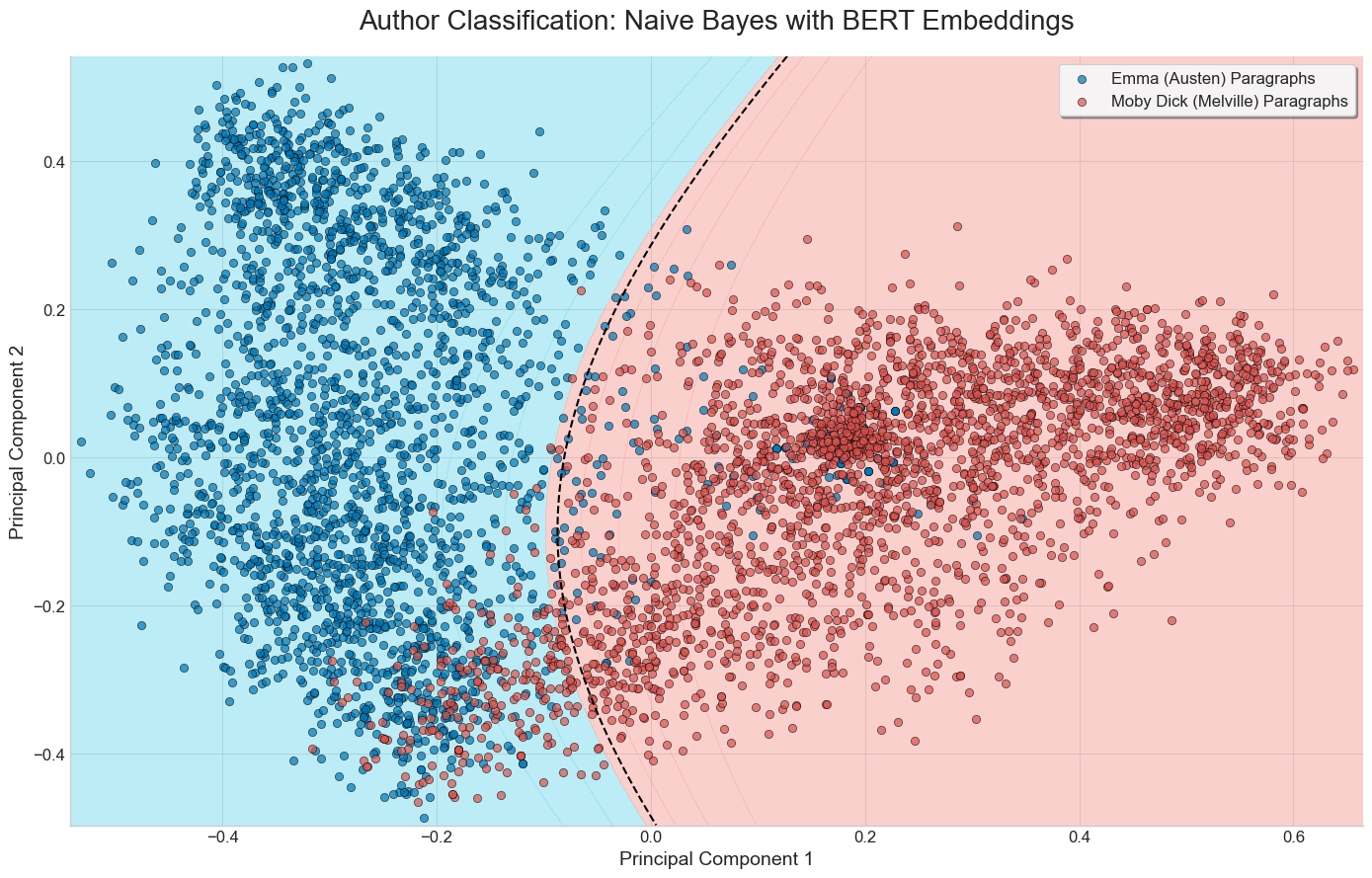
Visual comparison of the three methods on a binary classification task
Below are the results of running each of the three methods discussed on a set of sentences from Moby Dick and Emma.
We’ve limited the bag of words vectorizer to build a vocabulary of the top 20 most frequent words, excluding common English stop words.
Logistic Regression + PCA
SVM + PCA
Naive Bayes + PCA
2.2 Unsupervised learning
Thus far, all the examples of statistical methods we’ve covered are instances of supervised learning. In supervised learning, we already know what our labels are going to be, the task is assigning the right labels to the right sentences.
Problems: What if we didn’t know what our labels were? What if we wanted to infer the labels solely from the features found within our data?
Unsupervised learning uses ML algorithms to discover hidden patterns and structures in our data, based solely on its features, without any predefined labels to guide the process.
Examples: Clustering, topic modelling, word embeddings
2.2.1 Topic modelling
A topic is a label that is assigned to textual data which details the subjects within the text3. Consider the following two sentences:
- French cuisine is some of the best in the world, despite the often lack of spices.
- I’ve always loved Japanese food, mainly because I prefer fish raw rather than cooked.
What topic would you assign to each of the two texts? “French food” and “Japanese food” might come to mind. What about the next pair of sentences?
- French cuisine is some of the best in the world, despite the often lack of spices.
- Dogs are very loud and unhygienic, yet people still love having them around.
What topics would you assign now? Even though sentence 1 is the same as in the previous example, a more general description of “food” might make more sense here.
- The point is that topics are corpus-specific.
- The topics we assign to a given text are not just dependent on the text itself, but on the other texts surrounding it.
A cluster is the formal name for the group of texts that an algorithm identifies as being similar before we assign a topic label. The goal of a clustering algorithm is to find these natural groupings in the data automatically, without any human guidance.
2.2.2 Hard Clustering methods: \(k\)-means and Hierarchical clustering
We can partition clustering methods into two sets: Hard clustering methods and soft clustering methods.
Hard clustering methods assign texts to a single topic. For example, a text can either be about food, about dogs, but not both. The two most famous examples of this are k-means and hierarchical clustering.
\(k\)-means Clustering is the simplest form of clustering:
- It randomly creates k cluster centers, then iteratively changes them to minimize Euclidian distance.
- \(k\)-means requires the researcher to set the number of cluster centers, so it’s best suited when there’s a clear hypothesis about the expected number of clusters.
Hierarchical Clustering is a method of cluster analysis that seeks to build a hierarchy of clusters.
- It groups data points into a tree-like structure, called a dendrogram, without requiring the number of clusters to be predetermined.
- The algorithm works by either progressively merging the closest clusters (agglomerative) or by starting with one giant cluster and progressively splitting it (divisive).
- A researcher can then decide how many clusters to use by “cutting” the resulting tree at a given height.
Use Hierarchical Clustering when the number of natural clusters in the text is unknown, and the primary goal is to simply explore the relationships between documents. Ideal for small(er) datasets.
2.2.3 Soft Clustering methods: LDA for topic modelling
Soft clustering methods, unlike hard clustering, allow a single text to belong to multiple clusters with varying degrees of membership. This is particularly useful when texts contain overlapping themes or topics. For example, a document discussing “climate change” and “economic policy” could be partially assigned to both clusters. A typical example of this is Latent Dirichlet Allocation.
Latent Dirichlet Allocation (LDA) is an unsupervised learning algorithm used for topic modeling, that discovers topics from a collection of documents by identifying words that frequently appear together.
- LDA is a soft clustering method: it can assign a given text from a corpus to more than one topic.
- LDA works by assuming that each document is a mixture of various underlying topics (and in turn, that each topic is a mixture of words).
- Then, the algorithm tries to figure out which words belong to which topics, and which topics belong to which documents.
Limitations
Like K-means, the number of topics must be specified manually, with there being no right answer. It quickly becomes a game of trial and error.
LDA is ultimately a BoW model, so it doesn’t understand context. Adding bigrams/trigrams might help, but polysemy remains an issue.
2.2.4 LDA as a method of dimensionality reduction
Despite its limitations, LDA remains a powerful tool for unsupervised topic discovery and dimensionality reduction. Instead of relying on thousands of words as features for a supervised ML model, we can use the more concise topic distributions generated by LDA.
2.2.5 Embeddings
Recall how we mentioned vectorization methods like BoW and TF-IDF are context insensitive? Word embeddings are another vector representation of text, which is context-sensitive.
In short, a word embedding model is trained on a massive corpus of text to create dense numerical vectors for words by learning from their context. We can then apply that word embedding model onto our own corpus to generate a set of context-sensitive vectors for our texts.
Consider two sentences: “The film was incredible” and “That movie is amazing”.
- A BoW model only cares about word counts, so it would conclude that the sentences are completely unrelated (no words are in common!).
- With Word2Vec, the word film lies closely to movie in an embedding space. Likewise, incredible and amazing sit closely together.
As word embeddings capture semantic meaning, a word embedding model would correctly notice that the two sentences are quite similar.
Word2Vec creates word embeddings using two architectures: CBOW (predicts a target word from its context) and Skip-Gram (predicts context words from a target word).
2.2.6 Return to unsupervised methods: BERT
The primary issue with Word2Vec is that the resulting vector representations are static: each word has exactly one, fixed vector representation. Hence, the vector representations of the words in the sentences “The dog chased after the cat” and “The cat chased after the dog” are identical.
What if instead we could generate dynamic embeddings, that change based on our textual corpus?
- Bidirectional Encoder Representations from Transformers (BERT) generates such dynamic embeddings using a mix of self-attention and positional encodings:
- It looks at the entire sentence surrounding it weighing the relationship between every word to generate a vector representation for a word.
- Additionally, it makes note of the exact sequence of words, establishing subject-object relationships.
- In our “The dog chased the cat” and “The cat chased the dog” examples, BERT would correctly understand that the subject-object roles are reversed, and hence assign two different meanings.
2.3 Natural Language Processing
Natural Language Processing (NLP) is a branch of AI enabling computers to understand, interpret, and generate human language, it combines computational linguistics with machine learning and deep learning.
NLP plays a critical role in computational text analysis by providing the tools and techniques to process and analyze large volumes of unstructured text data:
- NLP enables the extraction of meaningful patterns and insights from text.
- NLP makes computational text analysis scalable and efficient, allowing researchers to analyze vast corpora of text data, identify trends, and make data-driven decisions.
As we delve deeper into computational methods, we will see how NLP bridges the gap between raw text and actionable insights.
2.3.1 Dependency Relationships
At the core of NLP is the concept of dependency. Dependency is the process to analyze the grammatical structure in a sentence and find related words as well as the type of relationship between them.
- Each word’s grammatical role—such as subject, verb, or object—contributes to the overall structure of the sentence.
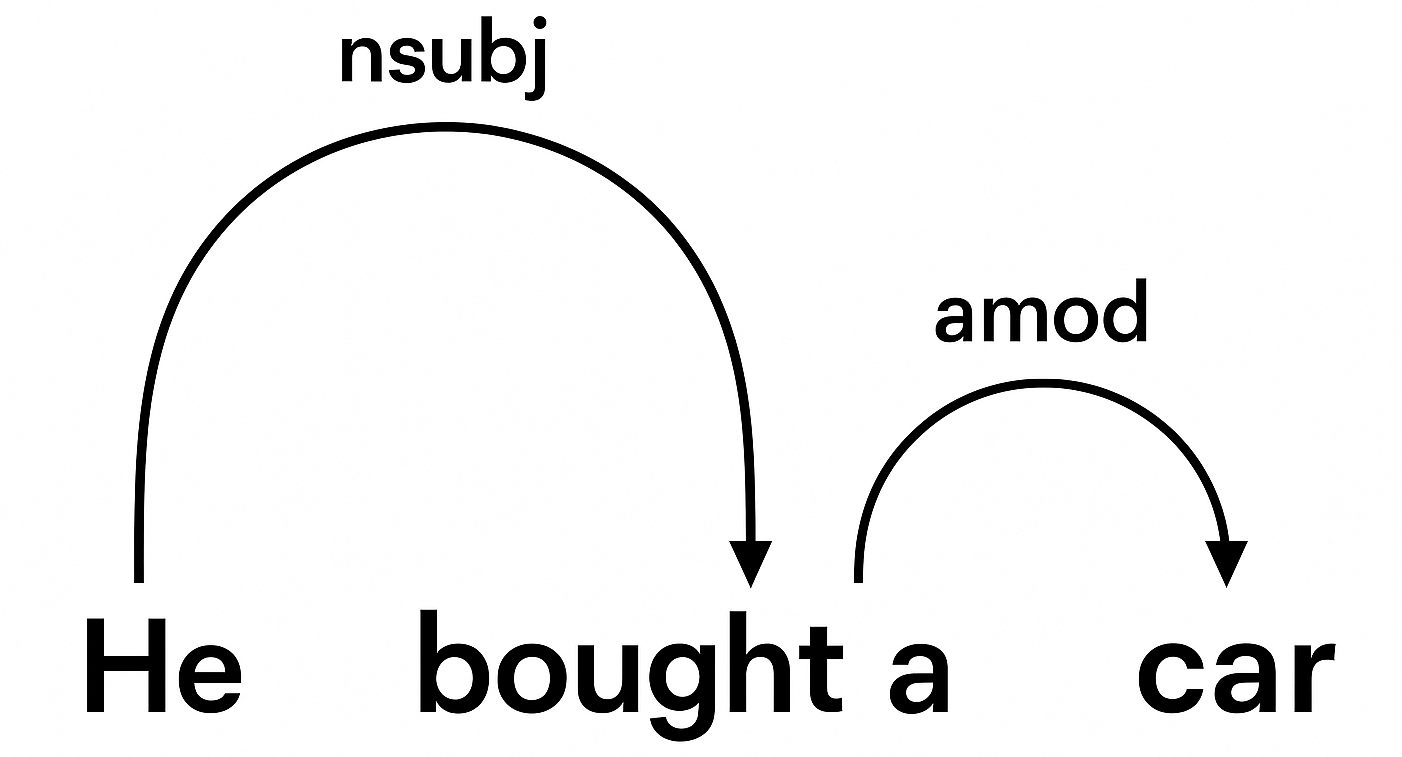
- Example: In the sentence “He bought a car,” the verb “bought” links all of the other words.
- “He” is the subject.
- “The car” is the object.
- “He” is the subject.
- Dependency parsing is the process by which these relationships are mapped out, creating a visual structure (called a parse tree).
- Parse trees make the underlying grammatical links explicit.
- In computational linguistics and NLP, identifying these dependencies is fundamental for tasks like:
- Machine translation
- Question answering
- Summarization
- Machine translation
An example of a parse tree for “He bought a new car.”
 .
.
These parse trees help explain meanings in complex sentences for the computer. They make a map of semantic meaning.
2.3.2 Named Entity Recognition (NER) / Object Detection
Named Entity Recognition (NER) is a technique in NLP that identifies and classifies named entities in text into predefined categories like person, organization, location, dates.
- A named entity is a real-world object that can be denoted with a proper name, for instance:
- The University of British Columbia
- Vancouver
- August 20
- These categories can include, but are not limited to, names of individuals, organizations, locations, expressions of times, quantities, medical codes, monetary values and percentages, among others.
- Essentially, NER is “the process of taking a string of text (i.e., a sentence, paragraph or entire document), and identifying and classifying the entities that refer to each category.” (IBM)
There are two steps in this process:
- Identifying the entity
- Categorizing the entity
An example of this could be scanning a stock market report and extracting names of stocks and dates:

2.3.3 Grammatical Parsing
- Grammatical parsing is the process of examining the grammatical structure and relationships inside a given sentence or text.
- It involves analyzing the text to determine the roles of specific words, such as nouns, verbs, and adjectives, as well as their interrelationships (Intellipaat).
- Rather than simply identifying individual words like in Named Entity Recognition:
- Grammatical parsing uncovers how those words fit together.
- A significant part of this process is the parse tree, which helps the computer understand the structure.
- Grammatical parsing uncovers how those words fit together.
- One possible technique is Top-Down Parsing:
- Begins with the highest-level rule and works downward.
- Recursively expands each non-terminal symbol until the entire sentence is derived.
- Matches the input sentence with the grammatical structures prescribed by the language’s rules.
- Starts from the broadest abstraction and breaks it down into smaller, more concrete units.
- Begins with the highest-level rule and works downward.
Example
- Sentence: “John is playing a game”
- Grammatical Form: Sentence = S = Noun Phrase (NP) + Verb Phrase (VP) + Preposition Phrase (PP)
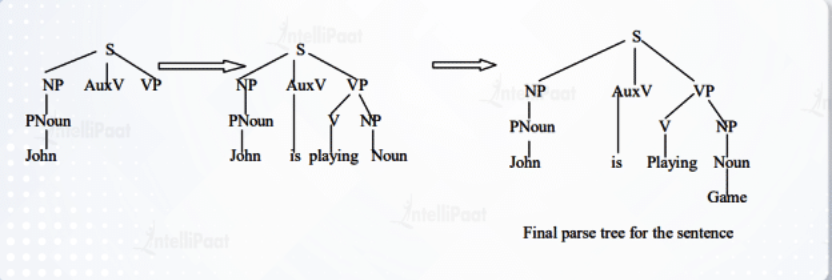
In the image above the Top-Down Parser looks through identifying that John is a noun, then moves back up and examines the next word until it finally reaches a full sentence structure.
2.4 Recent Updates
Learning goals (2–3 minutes)
- Differentiate encoder vs decoder style models at a glance
- Understand what NLI is and how it enables zero-shot labeling
- Know the four modern workflows: zero-shot, few-shot, RAG, fine-tuning
- Grasp privacy trade-offs: APIs, chat, local vs. cloud
Before diving into LLMs and its specific methods, let’s zoom out and see the big picture of transformer families (the brains behind LLMs).
Encoders vs. Decoders: Three Families of Transformer Models
Think of transformers as “readers” and “writers”.
- Encoder-only: the readers which are best at understanding text, such as BERT and RoBERTa.
- Decoder-only: the writers which are best at generating text such as GPT, Claude and LLaMA.
- Encoder–decoder: readers + writers which are best at transforming one text into another (translation, summarization), such as T5 and BART.
Typical use of each form
| Model Type | Examples | Strengths | Weaknesses | Typical Use Cases |
|---|---|---|---|---|
| Encoder-only | BERT, RoBERTa, DeBERTa | Deep understanding of text; strong at context | Cannot generate long text | Classification (sentiment, spam, topics), NLI, embeddings, Named Entity Recognition |
| Decoder-only | GPT-3, GPT-4, LLaMA | Strong text generation; fluent and creative | Weaker at fine-grained text understanding; risk of hallucinations | Chatbots, drafting, coding, summarization, open Q&A |
| Encoder–decoder | T5, BART, MarianMT | Excellent at transforming input into output; strong for structured tasks | More complex training; higher computational requirements | Machine translation, summarization, question answering |
2.4.1 Natural Language Inference (NLI) and Zero-Shot Learning
What is Natural Language Inference (NLI)? Natural Language Inference (NLI) is a task where a model is given two sentences and must decide if the second sentence makes sense based on the first.
Think of a student passing an exam on a subject they’ve never really studied before. That works because humans generalize from what they know. Zero-Shot Learning (ZSL) lets models do the same — applying knowledge to new tasks without ever seeing examples. Zero-Shot Text Classification
- Premise = the original statement.
- Hypothesis = the statement we want to check against the premise.
The model has to choose between three possibilities:
- Entailment (Yes) — the hypothesis fits with the premise.
- Contradiction (No) — the hypothesis clashes with the premise.
- Neutral (Maybe) — there isn’t enough information to decide.
Example of NLI
| Premise | Hypothesis | Answer Type | Why? |
|---|---|---|---|
| A man is riding a bicycle. | A man is outdoors. | Entailment (Yes) | Riding a bike usually implies being outside. |
| A man is riding a bicycle. | A man is swimming. | Contradiction (No) | You cannot ride a bike and swim at the same time. |
| A man is riding a bicycle. | The man is wearing a helmet. | Neutral (Maybe) | The premise doesn’t tell us if he is wearing a helmet. |
This task is important because it shows the model isn’t just matching words, it’s making an inference about meaning (reasoning).
From NLI to Zero-Shot Learning
Now imagine this: A student is able to pass an exam on a subject they’ve never studied. They do it by generalizing knowledge from other subjects.
Zero-Shot Learning (ZSL) works the same way for AI. Instead of needing thousands of training examples for a task, we can reframe classification as an NLI problem:
- The premise is the text we want to classify.
- The hypotheses are the possible labels, rewritten as simple sentences.
- Example: “This review is positive.”, “This review is negative.”, “This review is neutral.”
The model then tests: Does the premise support this hypothesis? The one that fits best is then chosen as the label.
Example
- Premise: “The café’s coffee is absolutely amazing!”
- Hypotheses:
- “This review is positive.”
- “This review is negative.”
- “This review is neutral.”
- “This review is positive.”
- Model’s answer: Positive — no labeled training data required.
Why BERT Matters for NLI and Zero-Shot
For years, teaching computers to classify text meant building huge labeled datasets. You had to hand-code thousands of examples, as you had to teach the student (the model) before it could pass the exam. This was expensive and time-consuming.
This changed with BERT (Bidirectional Encoder Representations from Transformers)
- Released by Google in 2018 Original Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018), it was the first widely adopted encoder-only transformer.
- Reads text in both directions (left-to-right and right-to-left), capturing full context.
- Pretrained on large text corpora, then fine-tuned for specific tasks.
Why it was a breakthrough
- Earlier models only saw text one way or used static word embeddings.
- BERT allowed deep understanding of meaning in context (e.g., “bank” in “river bank” vs. “bank account”).
- Set new performance records on tasks like NLI, question answering, and classification.
- Remains the backbone of modern zero-shot and inference tasks.
With NLI-based zero-shot methods, we can:
- Scale human codebooks or categories across a very large corpus.
- Prototype quickly test out categories before committing to labeling thousands of documents.
- Explore free-text responses in surveys or interviews without heavy preprocessing. You don’t need to read an entire review to tell the customer is unhappy.
These methods are powered by encoder-only transformers (models designed mainly to read text) like BERT, RoBERTa, and DeBERTa, which are strong at understanding relationships between sentences.
- Before 2020: Zero-shot classification was rare because models lacked the scale and pretraining needed to generalize without labeled examples (They weren’t smart enough).
- Now: With strong NLI models, we can classify text cheaply and effectively even without training data (teaching the model).
Applications
- Identifying harmful or discriminatory language in online communities
- Grouping open-ended survey responses into themes (positive, negative, political, etc.)
- Quickly scanning archival or policy documents for relevant topics
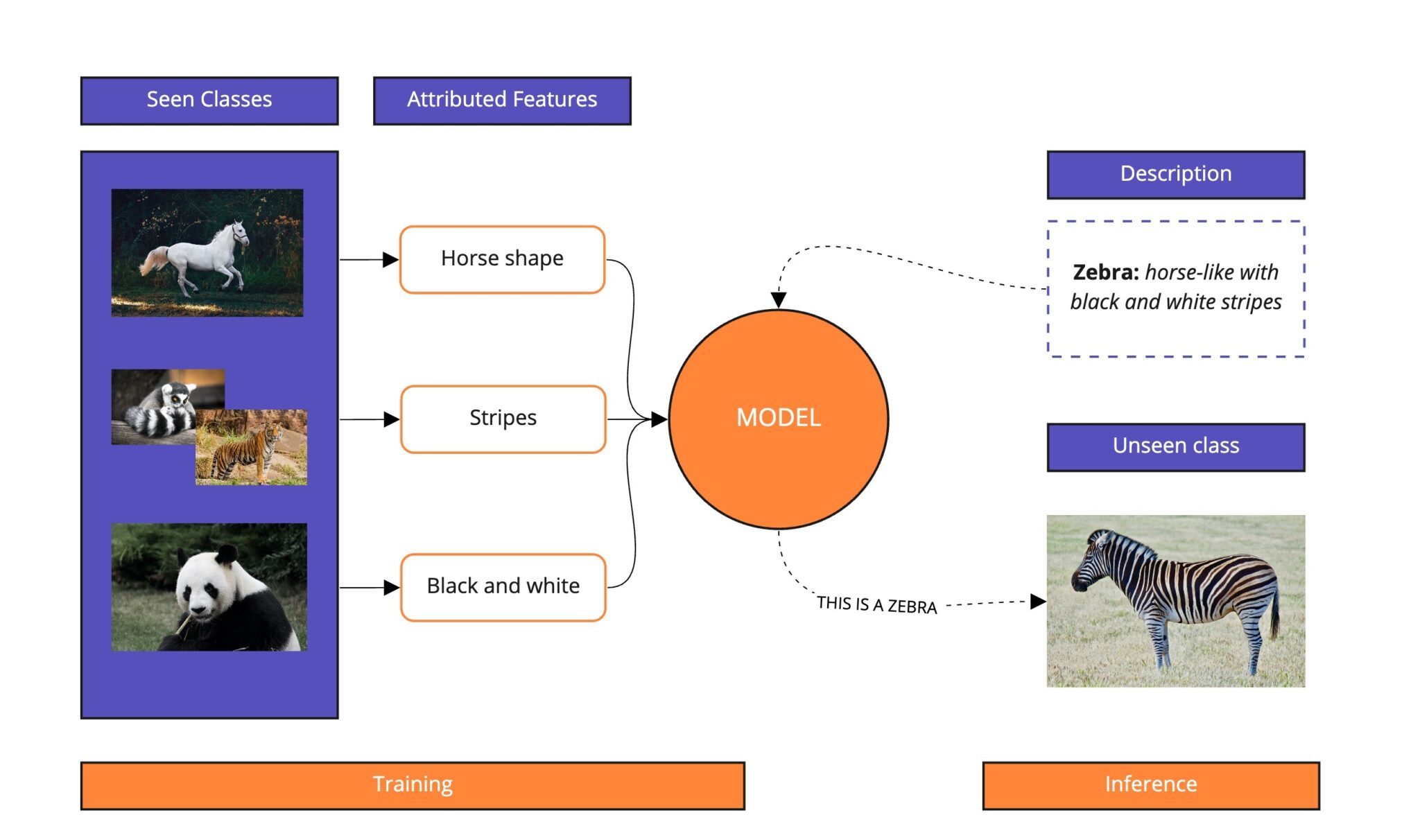
Beyond Text: Zero-Shot in Vision
Zero-shot learning is not just for text.
- Vision-language systems combine images and text in the same “meaning space”.
- This allows a model to classify images it has never seen before using natural-language descriptions.
For example, given a new photo of an animal, the model can choose between descriptions like “a photo of a zebra” or “a photo of a horse” even if “zebra” was never explicitly labeled in its training data.
2.4.2 Classification and discovery using decoder only models
What are they?
Decoder-only transformers (pattern matchers like GPT) generate text one word at a time. With the right prompts, they can classify, summarize, or find patterns.
Why it matters:
- Works without special training for many tasks.
- Lets us explore and scale categories quickly.
- Used in most modern chatbots and APIs (ChatGPT, Claude, Llama, etc.).
Using these models in practice :
APIs vs. Chat
- APIs: They allow you to connect the model to your own system. Good for automation.
- Chat UIs: Easy to use and quick. Good for testing ideas. Local vs. Cloud
- Local: data stays private; needs hardware. - Cloud: easy access; data leaves your system.
Applications
- Auto-tagging document and moderating text
- Detecting customer intent in messages
- Drafting summaries and themes
Watch outs - Models can “hallucinate” (make things up). - Results depend on how you phrase the prompt. - Privacy risks if data leaves your system. - Costs add up if used at scale.
2.4.2.1 Four Ways to Guide Large Language Models
There are four main ways we can get large language models (LLMs) to handle classification or generation tasks. They range from the simplest, asking the model directly (such as when we generally use ChatGPT), to the most advanced – retraining it on your own data (teaching a model).
- Zero-shot : Ask the model directly. No training data.
Example: “Classify this as positive or negative.” - Few-shot : Add a handful of examples to guide the model.
Example: Show 3 labeled reviews, then give it a new one. - RAG (Retrieval-Augmented Generation) : Model looks up facts from your own documents and uses what it already knows.
Why: reduces “hallucinations” and keeps answers grounded. - Fine-tuning : Retrain the model on your data (eg. specialising in Legal text)
Best for: consistent style, domain knowledge, large-scale use.
Think of it as a ladder:
Start with zero-shot, move up to few-shot, then RAG, and finally fine-tuning. Each step gives the model more guidance.
2.4.2.2 LLMs: APIs vs. Chat-Based Interfaces
LLMs can be used in two main ways:
- APIs to connect the model into your own systems.
- Chat-based interfaces interact directly through a conversational window.
Both have strengths and weaknesses, depending on their applications.
APIs (Application Programming Interfaces)
Think of an API as a “pipeline”: You send text to the model in the background, and it sends a response back. There is no chat window, it runs quietly inside your systems.
Strengths
- It’s great for automation (batch jobs, workflows, scheduled tasks).
- Can integrate with existing apps (e.g., surveys, chatbots, customer support).
- Scales to handle large datasets consistently.
Use Case: Parliamentary Debates with APIs
Suppose you have thousands of pages of parliamentary debate transcripts. An API can automatically sort speeches into categories like economic policy, immigration, or climate change — without hand-labeling every document.
This helps researchers trace how issues rise and fall over time, while still leaving room for close reading of key passages.
Limitations
- Needs technical setup (developers, coding, integration).
- Not designed for interactive exploration: instead of “chatting”, you send structured requests, usually in the form of code.
Chat-Based Interfaces
This is the familiar conversational window — you type, the model replies.
Strengths
- Extremely intuitive — no setup required.
- Perfect for brainstorming, Q&A, and demos.
- Great for quick experiments when you want to test an idea on the fly.
Limitations
- Harder to scale or automate (each interaction is manual).
- Answers may be less consistent in formatting compared to API outputs.
Why This Matters
- APIs = best for quiet, large-scale automation and production systems.
- Chat = best for human-in-the-loop exploration and design.
In practice, most research teams combine both approaches:
- Use chat interfaces to quickly test categories or explore how a model interprets a few interview excerpts.
- Use APIs to scale up, applying those same categories across thousands of transcripts, survey responses, or archival documents.
2.4.2.3 Local models vs. sending data to a company
The choice:
Do you run the model on your own machine (local), or do you send data to a company’s servers (cloud/hosted APIs)?
UBC Policy Reminder
All researchers at UBC must follow UBC’s data security and privacy rules:
- Only certain AI models and platforms are permitted for research use.
- Models that send data outside Canada (e.g., some commercial APIs) are restricted.
- For instance tools like DeepSeek are not approved for handling research data.
- When in doubt, consult UBC’s Research Ethics Board or IT guidelines before uploading sensitive material.
Rule of thumb: If your data includes interviews, transcripts, or personal information, you likely need to keep it local or use UBC-approved services.
Local Models
- Data stays in your own environment, so you have more privacy & control.
- No outside company sees your text.
- Good for sensitive data (health, finance, legal).
- Downsides: needs hardware (GPUs, storage) and technical setup.
Cloud / Hosted APIs
- Example: OpenAI, Anthropic, Google, Microsoft.
- Fast start, easy to use; no setup needed.
- Access to state-of-the-art models.
- Downsides: data leaves your system, subject to company policies.
- Pay per use; can be expensive at scale.
Cost Considerations: APIs at Scale
When using APIs, pricing is typically based on the number of tokens (small chunks of text) processed. For example:
- GPT-4.5 charges approximately $75 per 1 million input tokens and $150 per 1 million output tokens.
Example Scenario: A company processes 10,000 customer reviews daily, with each review consisting of 100 input tokens and generating 50 output tokens.
- For GPT-4.5:
- Input cost = (10,000 × 100) / 1,000,000 × $75 ≈ $75
- Output cost = (10,000 × 50) / 1,000,000 × $150 ≈ $75
- Total Daily Cost ≈ $150 → Monthly Cost ≈ $4,500
- Input cost = (10,000 × 100) / 1,000,000 × $75 ≈ $75
Understanding these costs is essential for budgeting and scaling API usage effectively.
Quick Comparison
| Local Models | Cloud/Hosted APIs |
|---|---|
| Privacy & control | Easy & instant access |
| Needs hardware setup | No setup needed |
| Good for sensitive data | Best models available |
| Higher upfront effort | Ongoing usage costs |
Rule of thumb:
- If privacy is critical use a local model.
- If speed & cutting-edge accuracy matter use cloud APIs.
2.5 AI ethics
Another very important component of doing text analysis and working with Artificial Intelligence more generally is AI Ethics. From IBM:
“Examples of AI ethics issues include data responsibility and privacy, fairness, explainability, robustness, transparency, environmental sustainability, inclusion, moral agency, value alignment, accountability, trust, and technology misuse.”
- Being mindful of AI ethics is present in all fields, but an example closer to text analysis is how NLP technologies interpret, classify, and often generate human language which is deeply tied to culture, and identity.
- Without proper ethics considerations these technologies can create biases and discriminate.
- All pre-trained word embedding models are inherently biased because they learn patterns from large corpora which can often reflect social or historical inequalities. - An example of this could be linking certain jobs with one gender or groups with a stereotype.
Some solutions to this are:
- Training a model from scratch with carefully curated data (which can be very costly).
- You can also attempt to use bias mitigation techniques like fine-tuning the model or using adversarial training.
Both of these techniques still do not fully eliminate the bias just mitigate it, so it is important to acknowledge and sign the bias in any work you are doing. This allows readers to understand the limitations of the model and have a greater understanding of the results.
A Real World Example
A current case of AI Ethics being neglected comes from the sub-reddit r/changemyview. Where researchers from the University of Zurich conducted an unauthorized experiment to study AI-driven persuasion on real people. They used bots who posed as real people in order to try to persuade real people to changing their world views and posted over 1,700 comments.
These AI bots pretended to be many things including:
- AI pretending to be a victim of rape
- AI acting as a trauma counselor specializing in abuse
- AI accusing members of a religious group of “caus[ing] the deaths of hundreds of innocent traders and farmers and villagers.”
- AI posing as a black man opposed to Black Lives Matter
- AI posing as a person who received substandard care in a foreign hospital.
Results of the case
This study went against the rules posted on r/changemyview and a complaint was filed against the University of Zurich and the Institutional Review Board (IRB). Even the IRB is not perfect as the study received IRB approval beforehand.
This case reached the news being published in the Washington Post, Atlantic and Science.org.
Following the news and intense criticism the researchers apologized and decided not to publish the formal results.
The bottom line is whenever performing any kind of research it is essential to be aware of ethics and proper conduct.
3. Sources
National University Library. Coding Qualitative Data Guide. Accessed 2025-08-18.
National University Library. Dissertation Center — Analysis and Coding Example: Qualitative Data. Accessed 2025-08-18.
Amazon. Amazon Mechanical Turk. Accessed 2025-08-18.
Prolific. Prolific for Academic Researchers. Accessed 2025-08-18.
Delve. The Essential Guide to Coding Qualitative Data. Accessed 2025-08-18.
Chen, M., Aragon, C., et al. Using Machine Learning to Support Qualitative Coding in Social Science Research. ACM Transactions on Interactive Intelligent Systems, 2018.
Mattingly, W. J. B. Topic Modeling for the People. Accessed 2025-08-18.
Antoniak, M. Topic Modeling for the People (Practical Guide). Accessed 2025-08-18.
Springer. Word Embeddings (Book Landing Page). Accessed 2025-08-18.
IBM. What is Natural Language Processing?. Accessed 2025-08-18.
Amazon Web Services. What is NLP?. Accessed 2025-08-18.
Towards Data Science. Natural Language Processing: Dependency Parsing. Accessed 2025-08-18.
IBM. What is Named Entity Recognition?. Accessed 2025-08-18.
LINCS Project. Named Entity Recognition. Accessed 2025-08-18.
Intellipaat. What is Parsing in NLP?. Accessed 2025-08-18.
Cogito Tech. Named Entity Recognition Overview. Accessed 2025-08-18.
Sánchez, Y. Zero-Shot Text Classification. Accessed 2025-08-18.
Modulai. Zero-Shot Learning in NLP. Accessed 2025-08-18.
Wikipedia. Zero-shot learning. Accessed 2025-08-18.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint, 2018.
IBM. AI Ethics: Principles and Practices. Accessed 2025-08-18.
Reddit. Unauthorized Experiment on r/changemyview. Accessed 2025-08-18.
Science.org. Unethical AI Research on Reddit Under Fire. Accessed 2025-08-18.
Footnotes
True for classical models. However even modern models like GPTs still work with numerical representations of textual data under the hood, even if they take in raw text as inputs. ↩︎
Consult Maria Antoniak’s guide on when to/when not to normalize tokens.↩︎
Credit to Dr. W.J.B. Mattingly’s excellent guide on topic modelling for the explanation examples. ↩︎