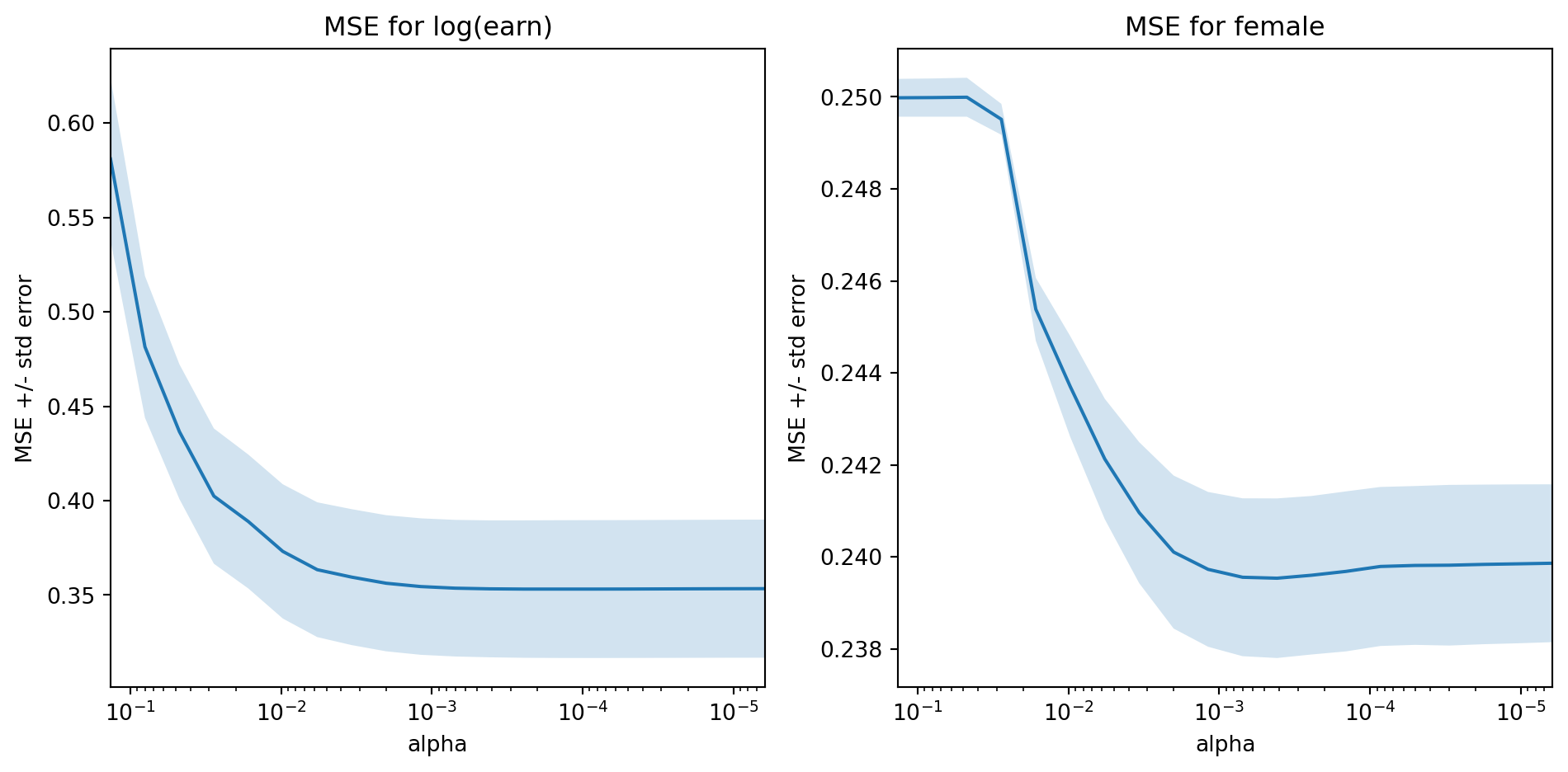
In matching we said that we could use flexible machine learning estimators for \(\Er[Y|D,X]\) and \(P(D=1|X)\) and plug them into the doubly robust estimator
First order condition at \(f_\theta = f_0\) gives \[
0 = \Er\left[ (y - f_0(x))\partial_x \log p(x) + (\theta - f_0'(x)) \right]
\]
Orthogonal scores via Two Other Methods
“Orthogonal” suggests ideas from linear algebra will useful, and they are
Projection: take orthogonal to \(\eta_0\) projection of moments
Riesz representer
Example: Gender Wage Gap
Data
imports
import matplotlib.pyplot as pltimport numpy as npimport pandas as pdfrom sklearn.model_selection import cross_val_predictfrom sklearn import linear_modelfrom sklearn.preprocessing import PolynomialFeaturesimport statsmodels as smimport statsmodels.formula.api as smffrom statsmodels.iolib.summary2 import summary_colimport osimport requests
url ='https://www.nber.org/morg/annual/morg23.dta'local_filename ='data/morg23.dta'ifnot os.path.exists(local_filename): response = requests.get(url)withopen(local_filename, 'wb') asfile:file.write(response.content)cpsall=pd.read_stata(local_filename)# take subset of data just to reduce computation timecps = cpsall.sample(30000, replace=False, random_state=0)cps["female"] = (cps.sex==2)cps["log_earn"] = np.log(cps["earnwke"])cps["log_uhours"] = np.log(cps.uhourse)cps["log_hourslw"] = np.log(cps.hourslw)cps.replace(-np.inf, np.nan, inplace=True)cps["nevermarried"] = cps.marital==7cps["wasmarried"] = (cps.marital >=4) & (cps.marital <=6)cps["married"] = cps.marital <=3cps.describe()
hurespli
hhnum
county
centcity
smsastat
icntcity
smsa04
relref95
age
spouse
...
ym
ch02
ch35
ch613
ch1417
ch05
ihigrdc
log_earn
log_uhours
log_hourslw
count
29981.000000
30000.000000
30000.000000
24769.000000
29700.000000
3637.000000
30000.000000
30000.000000
30000.0000
15166.000000
...
30000.000000
30000.000000
30000.000000
30000.000000
30000.000000
30000.000000
20678.000000
15437.000000
16367.000000
16687.000000
mean
1.250325
1.039333
25.706267
1.940813
1.190067
1.407479
3.663267
42.799233
49.4125
1.587037
...
752.582333
0.054800
0.058133
0.127433
0.082300
0.093467
12.474732
6.867861
3.595133
3.566121
std
0.623380
0.208777
61.805660
0.715204
0.392361
0.954135
2.592586
3.839065
19.1787
0.702528
...
6.883342
0.227593
0.233999
0.333463
0.274826
0.291090
2.434483
0.820460
0.394975
0.488110
min
0.000000
1.000000
0.000000
1.000000
1.000000
1.000000
0.000000
40.000000
16.0000
1.000000
...
741.000000
0.000000
0.000000
0.000000
0.000000
0.000000
0.000000
-3.506558
0.000000
0.000000
25%
1.000000
1.000000
0.000000
1.000000
1.000000
1.000000
0.000000
40.000000
33.0000
1.000000
...
747.000000
0.000000
0.000000
0.000000
0.000000
0.000000
12.000000
6.461468
3.688879
3.555348
50%
1.000000
1.000000
0.000000
2.000000
1.000000
1.000000
4.000000
41.000000
50.0000
2.000000
...
753.000000
0.000000
0.000000
0.000000
0.000000
0.000000
12.000000
6.907755
3.688879
3.688879
75%
1.000000
1.000000
27.000000
2.000000
1.000000
1.000000
6.000000
42.000000
65.0000
2.000000
...
759.000000
0.000000
0.000000
0.000000
0.000000
0.000000
14.000000
7.387090
3.688879
3.688879
max
10.000000
4.000000
810.000000
3.000000
2.000000
7.000000
7.000000
59.000000
85.0000
15.000000
...
764.000000
1.000000
1.000000
1.000000
1.000000
1.000000
18.000000
9.286597
4.595120
4.595120
8 rows × 58 columns
Partial Linear Model
def partial_linear(y, d, X, yestimator, destimator, folds=3):"""Estimate the partially linear model y = d*C + f(x) + e Parameters ---------- y : array_like vector of outcomes d : array_like vector or matrix of regressors of interest X : array_like matrix of controls mlestimate : Estimator object for partialling out X. Must have ‘fit’ and ‘predict’ methods. folds : int Number of folds for cross-fitting Returns ------- ols : statsmodels regression results containing estimate of coefficient on d. yhat : cross-fitted predictions of y dhat : cross-fitted predictions of d """# we want predicted probabilities if y or d is discrete ymethod ="predict"ifFalse==getattr(yestimator, "predict_proba",False) else"predict_proba" dmethod ="predict"ifFalse==getattr(destimator, "predict_proba",False) else"predict_proba"# get the predictions yhat = cross_val_predict(yestimator,X,y,cv=folds,method=ymethod) dhat = cross_val_predict(destimator,X,d,cv=folds,method=dmethod) ey = np.array(y - yhat) ed = np.array(d - dhat) ols = sm.regression.linear_model.OLS(ey,ed).fit(cov_type='HC0')return(ols, yhat, dhat)
Notes: [1] R² is computed without centering (uncentered) since the model does not contain a constant. [2] Standard Errors are heteroscedasticity robust (HC0)
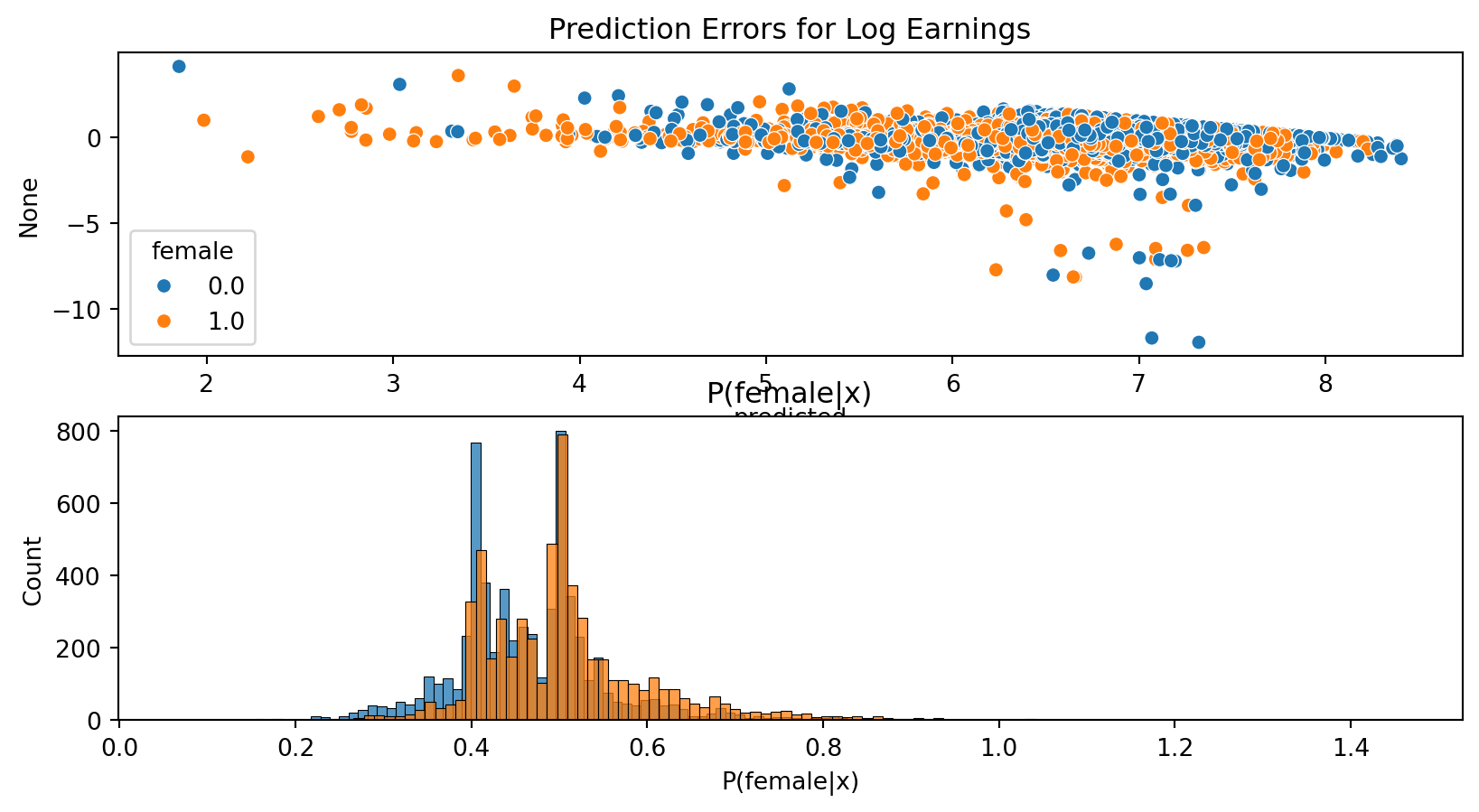
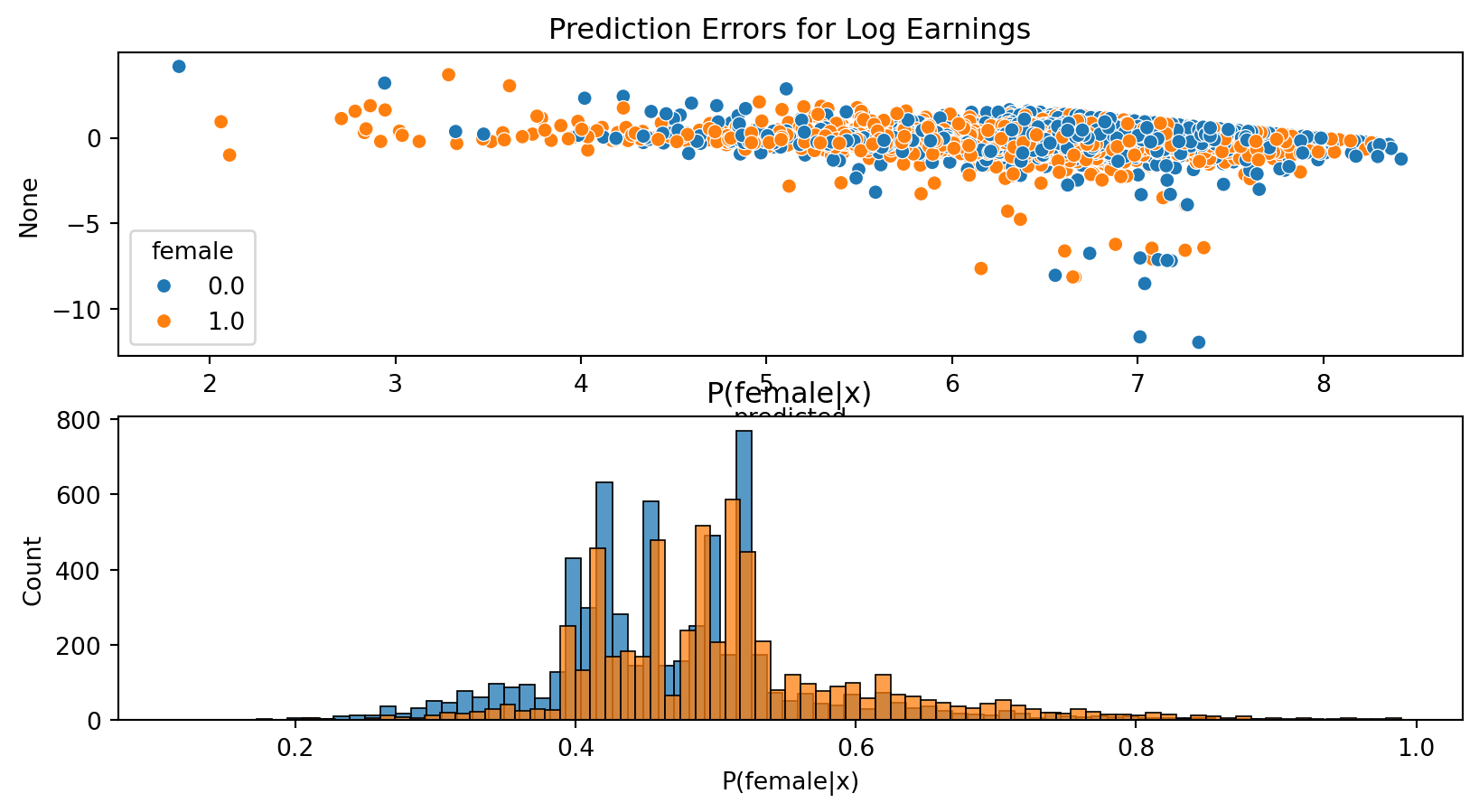
Examining Predictions
Code
import seaborn as sns# Visualize predictionsdef preddf(pl): df = pd.DataFrame({"logearn":logearn,"predicted":pl[1],"female":female,"P(female|x)":pl[2]})return(df)def plotpredictions(df) : fig, ax = plt.subplots(2,1) plt.figure() sns.scatterplot(x = df.predicted, y = df.logearn-df.predicted, hue=df.female, ax=ax[0]) ax[0].set_title("Prediction Errors for Log Earnings") sns.histplot(df["P(female|x)"][df.female==0], kde =False, label ="Male", ax=ax[1]) sns.histplot(df["P(female|x)"][df.female==1], kde =False, label ="Female", ax=ax[1]) ax[1].set_title('P(female|x)')return(fig)fig=plotpredictions(preddf(pl_lasso))fig.show()
[LightGBM] [Info] Total Bins 299
[LightGBM] [Info] Number of data points in the train set: 10156, number of used features: 31
[LightGBM] [Info] Start training from score 6.875225
[LightGBM] [Info] Total Bins 298
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] Start training from score 6.867727
[LightGBM] [Info] Total Bins 296
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] Start training from score 6.871366
[LightGBM] [Info] Total Bins 295
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] Start training from score 6.873900
[LightGBM] [Info] Total Bins 294
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 30
[LightGBM] [Info] Start training from score 6.866147
[LightGBM] [Info] Number of positive: 5021, number of negative: 5135
[LightGBM] [Info] Total Bins 299
[LightGBM] [Info] Number of data points in the train set: 10156, number of used features: 31
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.494388 -> initscore=-0.022451
[LightGBM] [Info] Start training from score -0.022451
[LightGBM] [Info] Number of positive: 5004, number of negative: 5153
[LightGBM] [Info] Total Bins 298
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.492665 -> initscore=-0.029341
[LightGBM] [Info] Start training from score -0.029341
[LightGBM] [Info] Number of positive: 5011, number of negative: 5146
[LightGBM] [Info] Total Bins 296
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.493354 -> initscore=-0.026584
[LightGBM] [Info] Start training from score -0.026584
[LightGBM] [Info] Number of positive: 5033, number of negative: 5124
[LightGBM] [Info] Total Bins 295
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 31
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.495520 -> initscore=-0.017919
[LightGBM] [Info] Start training from score -0.017919
[LightGBM] [Info] Number of positive: 5003, number of negative: 5154
[LightGBM] [Info] Total Bins 294
[LightGBM] [Info] Number of data points in the train set: 10157, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.492567 -> initscore=-0.029735
[LightGBM] [Info] Start training from score -0.029735
coef std err t P>|t| 2.5 % 97.5 %
d -0.166006 0.010406 -15.952984 2.716020e-57 -0.186401 -0.145611
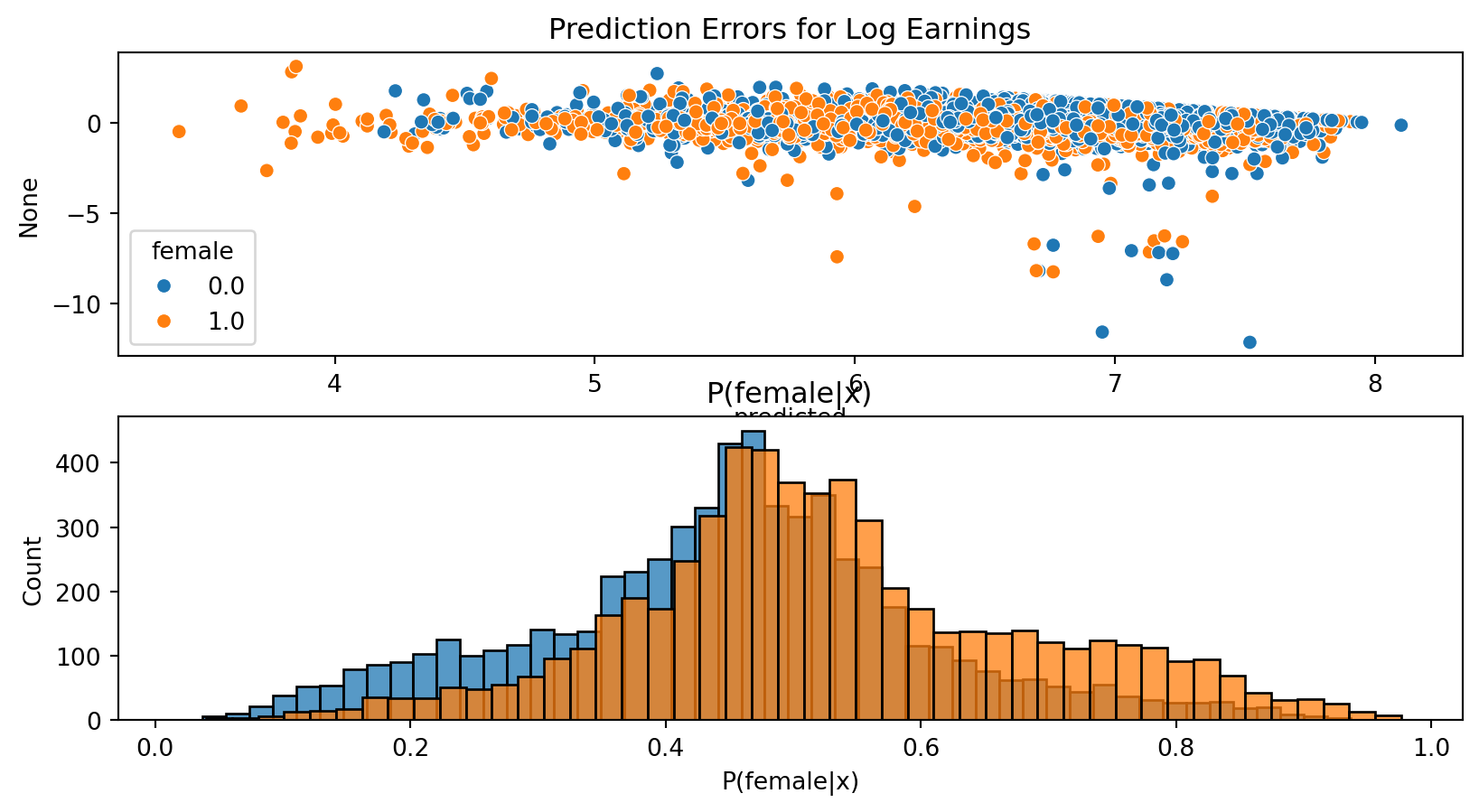
Visualizing Predictions: Trees
Code
plotpredictions(dmlpreddf(dml_plr_gbt)).show()
<Figure size 960x480 with 0 Axes>
Interactive Regression Model
Similar to matching, the partially linear regression model can suffer from misspecification bias if the effect of \(D\) varies with \(X\)
Interactive regression model: \[
\begin{align*}
Y & = g_0(D,X) + U \\
D & = m_0(X) + V
\end{align*}
\]
Mechanics same as matching heterogeneous effects
Orthogonal moment condition is same as doubly robust matching
[LightGBM] [Info] Total Bins 257
[LightGBM] [Info] Number of data points in the train set: 4285, number of used features: 27
[LightGBM] [Info] Start training from score 7.001738
[LightGBM] [Info] Total Bins 259
[LightGBM] [Info] Number of data points in the train set: 4285, number of used features: 27
[LightGBM] [Info] Start training from score 7.023577
[LightGBM] [Info] Total Bins 269
[LightGBM] [Info] Number of data points in the train set: 4286, number of used features: 28
[LightGBM] [Info] Start training from score 7.006350
[LightGBM] [Info] Total Bins 278
[LightGBM] [Info] Number of data points in the train set: 4179, number of used features: 29
[LightGBM] [Info] Start training from score 6.727922
[LightGBM] [Info] Total Bins 273
[LightGBM] [Info] Number of data points in the train set: 4179, number of used features: 30
[LightGBM] [Info] Start training from score 6.724012
[LightGBM] [Info] Total Bins 270
[LightGBM] [Info] Number of data points in the train set: 4178, number of used features: 27
[LightGBM] [Info] Start training from score 6.730945
[LightGBM] [Info] Number of positive: 4179, number of negative: 4285
[LightGBM] [Info] Total Bins 293
[LightGBM] [Info] Number of data points in the train set: 8464, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.493738 -> initscore=-0.025049
[LightGBM] [Info] Start training from score -0.025049
[LightGBM] [Info] Number of positive: 4179, number of negative: 4285
[LightGBM] [Info] Total Bins 288
[LightGBM] [Info] Number of data points in the train set: 8464, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.493738 -> initscore=-0.025049
[LightGBM] [Info] Start training from score -0.025049
[LightGBM] [Info] Number of positive: 4178, number of negative: 4286
[LightGBM] [Info] Total Bins 294
[LightGBM] [Info] Number of data points in the train set: 8464, number of used features: 30
[LightGBM] [Info] [binary:BoostFromScore]: pavg=0.493620 -> initscore=-0.025521
[LightGBM] [Info] Start training from score -0.025521
Knaus (2022) : approachable review of DML for doubly robust matching
References
Belloni, Alexandre, Victor Chernozhukov, and Christian Hansen. 2014. “Inference on Treatment Effects After Selection Among High-Dimensional Controls†.”The Review of Economic Studies 81 (2): 608–50. https://doi.org/10.1093/restud/rdt044.
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, and Whitney Newey. 2017. “Double/Debiased/Neyman Machine Learning of Treatment Effects.”American Economic Review 107 (5): 261–65. https://doi.org/10.1257/aer.p20171038.
Chernozhukov, Victor, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. 2018. “Double/Debiased Machine Learning for Treatment and Structural Parameters.”The Econometrics Journal 21 (1): C1–68. https://doi.org/10.1111/ectj.12097.
Chernozhukov, Victor, Christian Hansen, and Martin Spindler. 2015. “Valid Post-Selection and Post-Regularization Inference: An Elementary, General Approach.”Annual Review of Economics 7 (1): 649–88. https://doi.org/10.1146/annurev-economics-012315-015826.
Knaus, Michael C. 2022. “Double machine learning-based programme evaluation under unconfoundedness.”The Econometrics Journal 25 (3): 602–27. https://doi.org/10.1093/ectj/utac015.
Oliver Hines, Karla Diaz-Ordaz, Oliver Dukes, and Stijn Vansteelandt. 2022. “Demystifying Statistical Learning Based on Efficient Influence Functions.”The American Statistician 76 (3): 292–304. https://doi.org/10.1080/00031305.2021.2021984.